

Herzlich Willkommen!
Herzlich Willkommen auf dem RWTH-Blog rund um das Thema Forschungsdatenmanagement (FDM).
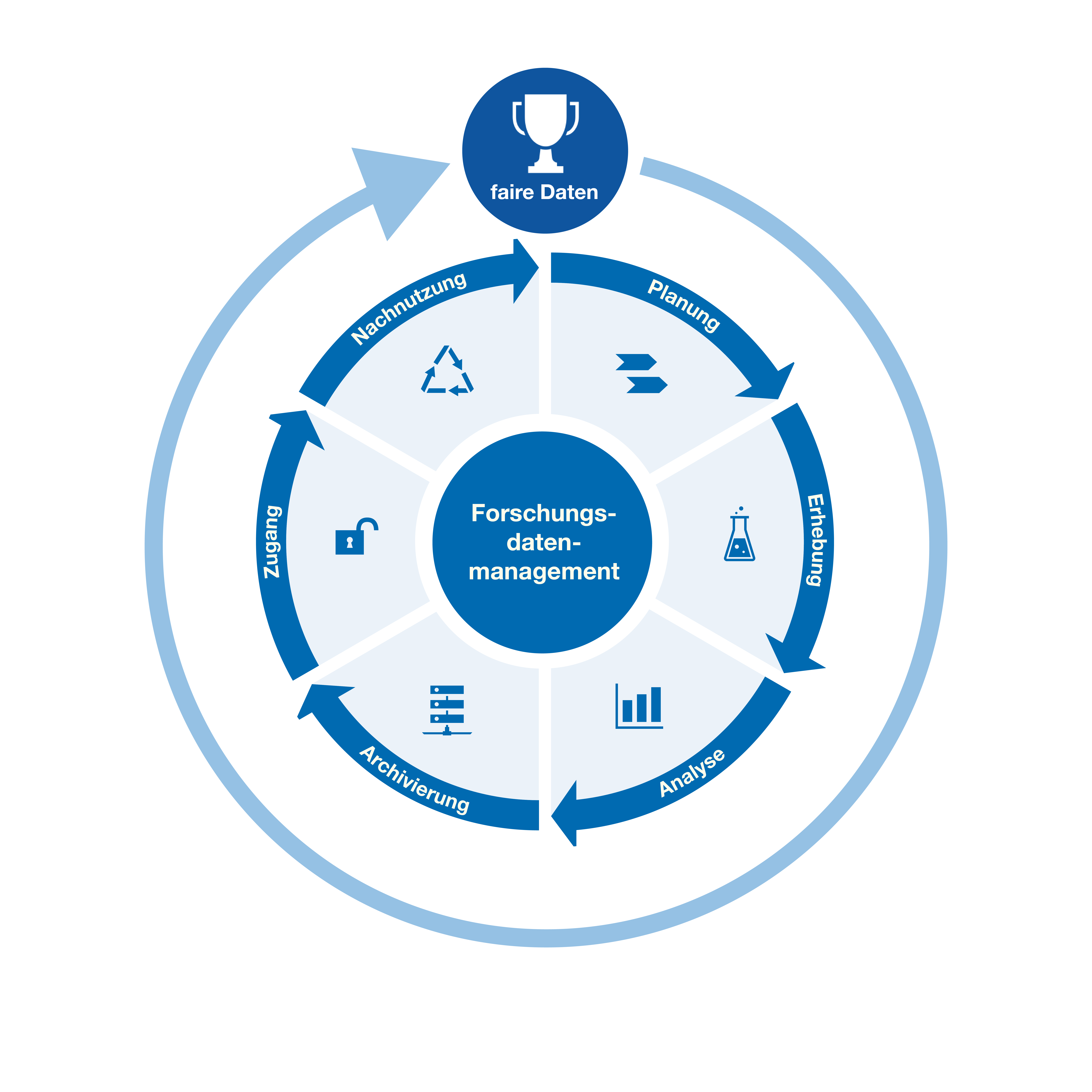
Der Datenlebenszyklus; Quelle: FDM-Team RWTH Aachen
Alle Forschende betreiben Datenmanagement – ganz gleich ob es sich bei dem Forschungsbereich um Geistes- und Sozialwissenschaften, Lebenswissenschaften, Naturwissenschaften oder Ingenieurwissenschaften handelt: Überall werden Daten erhoben, erfasst und ausgewertet.
Dieser Blog widmet sich in wöchentlichen Beiträgen der umfassenden Thematik des Managements von Forschungsdaten.
Neben den vorhandenen Beratungs- und Weiterbildungsangeboten wurde diese News-Plattform geschaffen, um über aktuelle Entwicklungen, anstehende Veranstaltungen an der RWTH Aachen und anderer Einrichtungen sowie über RWTH-Best Practices und Use Cases zu informieren.
Der Blog ergänzt mit wöchentlichen Beiträgen die FDM-Webseiten der RWTH, die mit anschaulichen Basisinformationen eine gute Grundlage bilden. Das gemeinsame Ziel: Ein planvolles und gut strukturiertes Forschungsdatenmanagement. Für alle.
Viel Spaß beim Lesen!
AKTUELLE BEITRÄGE
- Erstes Nutzendentreffen von Coscine.nrw
- Teilnahme an der Coscine-Umfrage
- Zentrale FDM-Services an der RWTH: RDMO
- Data Champions an der RWTH: Carolin Victoria Schneider
- Beitragsreihe: Zentrale FDM-Services an der RWTH
- FDM-Werkstatt 2024 – Tag 3
Alle aktuellen Beiträge ansehen …
USE CASES
- FDM Use Case I: SFB 985 – Funktionelle Mikrogele und Mikrogelsysteme
- FDM Use Case II – Lehrstuhl für Technische Thermodynamik (LTT)
- Call for Papers: Beiträge zur Planung des Datenmanagements gesucht
- Das war der Tag der Forschungsdaten 2022 – Ein Blick in den FDM-Kompass der RWTH
- Eine wirklich gute Idee – Der neue FDM-Podcast: IDEA
Mehr aus der RWTH-Praxis erfahren …
FDM-FLYER
Alle Informationen zum Forschungsdatenmanagement an der RWTH Aachen entnehmen Sie dem RWTH FDM-Flyer.


