

Welcome!
Welcome to the RWTH Blog around the topic of Research Data Management (RDM).
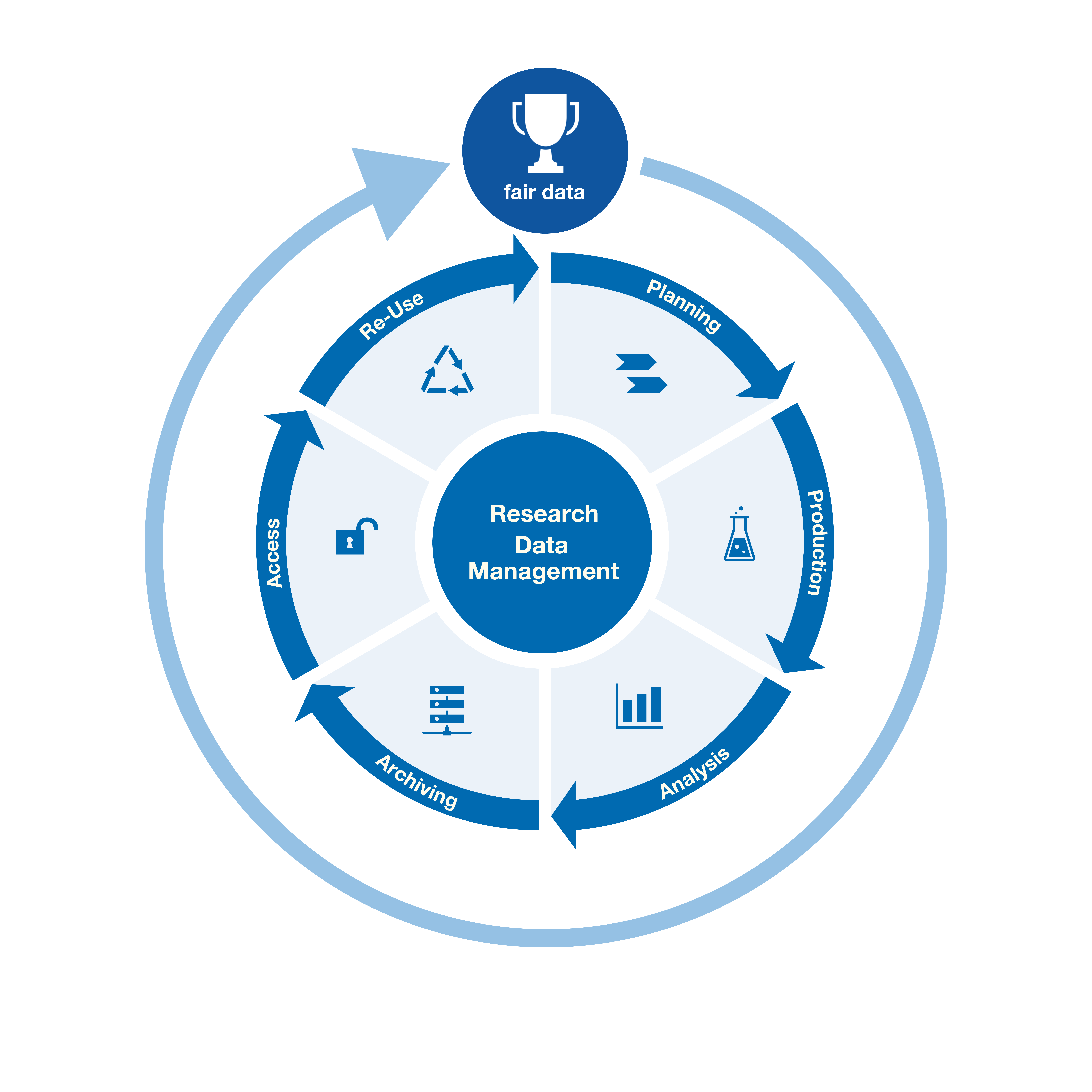
The Data Life Cycle, Source: RDM Team RWTH Aachen University
All researchers engage in data management – regardless of whether the research area is humanities and social sciences, life sciences, natural sciences or engineering: Data is collected, recorded and analyzed everywhere.
This blog is dedicated to the broad topic of Research Data Management in weekly posts.
In addition to the advising services and continuing education offers, this news platform was created to provide information about current developments, upcoming events at RWTH and other institutions, and RWTH best practices and use cases.
The blog supplements the RDM web pages of RWTH with weekly contributions, which form a good basis with descriptive basic information. The common goal: A planned and well-structured Research Data Management. For everyone.
Have fun reading!
RDM Flyer
All information about Research Data Management at RWTH Aachen University can be found in the RWTH RDM Flyer.
CURRENT POSTS
- RDM Checklist: Be Well Prepared for Your Vacation
- Publishing Research Data: Questions to Clarify in Advance
- Creative Commons Licenses Explained Simply
- Where Should I Store My Research Data? A Decision-Making Guide for RWTH
- ELN@RWTH: Digitizing Research Documentation
- From Alexandria to the World Wide Web: A Brief History of Research Data Management
USE CASES
- FDM Use Case I: SFB 985 – Funktionelle Mikrogele und Mikrogelsysteme
- FDM Use Case II – Lehrstuhl für Technische Thermodynamik (LTT)
- Asynchronous Tracking and Description of Research Data Changes in Distributed Systems With Interoperable Metadata
- Call For Papers: Contributions to Data Management Planning Sought
- This Was Research Data Day 2022 – A Look at The RWTH’s RDM-Compass
Learn more from RWTH practice …



