
Archive for March, 2020
On the importance of privacy metadata for process mining
This post is by Majid Rafiei, Scientific Assistant in the Process And Data Science group at RWTH Aachen University. Contact him via email for further inquiries.
Event logs are the type of data used by process mining algorithms to provide valuable insights regarding the real processes running in a company, organization, hospital, university, etc. However, they often contain sensitive private information that should be analyzed responsibly.
Privacy issues in process mining are recently receiving more attention. Privacy-preserving techniques need to modify the original data, yet, at the same time, they are supposed to preserve the data utility. Different data utility definitions can be used depending on the sensitivity of certain aspects and the goal of the analysis. Privacy-preserving transformations of the data may lead to incorrect or misleading analysis results. Hence, new infrastructures need to be designed for publishing the privacy-aware event data whose aim is to provide metadata regarding the privacy-related transformations on event data without revealing details of privacy techniques or the protected information.
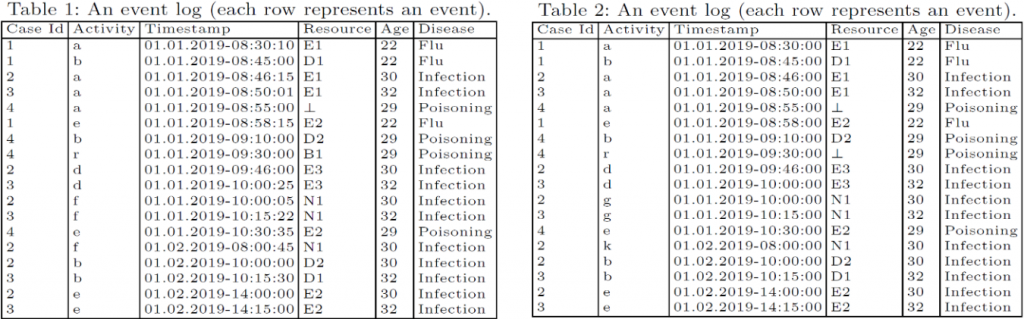
Compare Table 1 with Table 2. They both look like an original event log, right? Can you recognize the relation between these two tables? If one of them was derived from another one, which one is the original? How did the derivation happen? What are the weaknesses of the analyses done on the derived event log?
In fact, Table 2 is derived from Table 1 by randomly substituting some activities (f was substituted with g and k), generalizing the timestamps (the timestamps got generalized to the minutes level), and suppressing some resources (B1 was suppressed). Hence, a performance analysis based on Table 2 may not be as accurate as the original event log, the process model discovered from Table 2 contains some fake activities, and the social network of resources is incomplete.
We have a paper under review to address such challenges by proposing privacy metadata for process mining.
Enhanced Discovery of Uniwired Petri Nets Using eST-Miner
This post is by Lisa Mannel, Scientific Assistant in the Process And Data Science group at RWTH Aachen University. Contact her via email for further inquiries.
More and more processes executed in companies are supported by information systems which record events. Extracting events related to a process results in an event log. Each event in such a log has a name identifying the executed activity (activity name), a case id specifying the respective instance of the process, a time when the event was observed (timestamp), and possibly other data related to the activity and/or process instance. In process discovery, a process model is constructed aiming to reflect the behavior defined by the given event log: the observed events are put into relation to each other, pre-conditions, choices, concurrency, etc. are discovered, and brought together in a process model.
Process discovery is non-trivial for a variety of reasons. The behavior recorded in an event log cannot be assumed to be complete, since behavior allowed by the process specification might simply not have happened yet. Additionally, real-life event logs often contain noise, and finding a balance between filtering this out and at the same time keeping all desired information is often a non-trivial task. Ideally, a discovered model should be able to produce the behavior contained within the event log, not allow for unobserved behavior, represent all dependencies between the events, and at the same time be simple enough to be understood by a human interpreter. It is rarely possible to fulfill all these requirements simultaneously. Based on the capabilities and focus of the used algorithm, the discovered models can vary greatly, and different trade-offs are possible.
Our discovery algorithm eST-Miner [1] aims to combine the capability of finding complex control-flow structures like longterm-dependencies with an inherent ability to handle low-frequent behavior while exploiting the token-game to increase efficiency. Similar to region-based algorithms, the basic idea is to evaluate all possible places to discover a set of fitting ones. Efficiency is significantly increased by skipping uninteresting sections of the search space based on previous results [2]. This may decrease computation time immensely compared to evaluating every single candidate place, while still providing guarantees with regard to fitness and precision. Implicit places are removed in a post-processing step to simplify the model.
In [3] we introduce the subclass of uniwired Petri nets as well as a variant of eST-Miner discovering such nets. In uniwired Petri nets all pairs of transitions are connected by at most one place, i.e. there is no pair of transitions (a1 , a2) such that there is more than one place with an incoming arc from a1 and an outgoing arc to a2. Still being able to model long-term dependencies, these Petri nets provide a well-balanced trade-off between simplicity and expressiveness, and thus introduce a very interesting representational bias to process discovery. Constraining ourselves to uniwired Petri nets allows for a massive decrease in computation time compared to the basic algorithm by utilizing the uniwiredness requirement to skip an astonishingly large part of the search space. Additionally, the number of returned implicit places, and thus the complexity of post-processing, is greatly reduced.
For details we refer the reader to the original papers [1,3]. The basic eST- Miner, as well as the uniwired variant, take an event log and user-definable parameter τ as input. Inspired by language-based regions, the basic strategy of the approach is to begin with a Petri net, whose transitions correspond exactly to the activities used in the given log. From the finite set of unmarked, intermediate places a subset of fitting places is inserted. A place is considered fitting, if at least a fraction of τ traces in the event log is fitting, thus allowing for local noise-filtering. To increase efficiency, the candidate space is organized as a set of trees, where uninteresting subtrees can be cut off during traversal, significantly increasing time and space efficiency.
While the basic algorithm maximizes precision by guaranteeing to traverse and discover all possible fitting places, the uniwired variant chooses the most interesting places out of a selection of fitting candidates wiring the same pair of transitions. Subtrees containing only places that wire the same pair of transitions can be cut off. The output Petri net is no longer unique but highly dependent on the traversal and selection strategy. The approach presented in [3] prioritizes places with few arcs. Between places with the same number of arcs, places with high token-throughput are preferred. This strategy often allows us to discover adequate models, but fails in the presence of long loops which require places with more arcs. To overcome this restriction, we propose to use a reversed strategy, prioritizing places with high token throughput and using the number of arcs as a second criteria. This might slightly decrease the fraction of cut-off candidates but is expected to greatly increase model quality.
The running time of the eST-Miner variants strongly depends on the number of candidate places skippable during the search for fitting places. For the basic approach ([1]) our experiments show that 40-90 % of candidate places are skipped, depending on the log. The uniwired variant ([3]) has proven to find usable models while evaluating less than 1 % of the candidate space in all test cases (Figure 1), thus immensely speeding up the discovery (Figure 2).
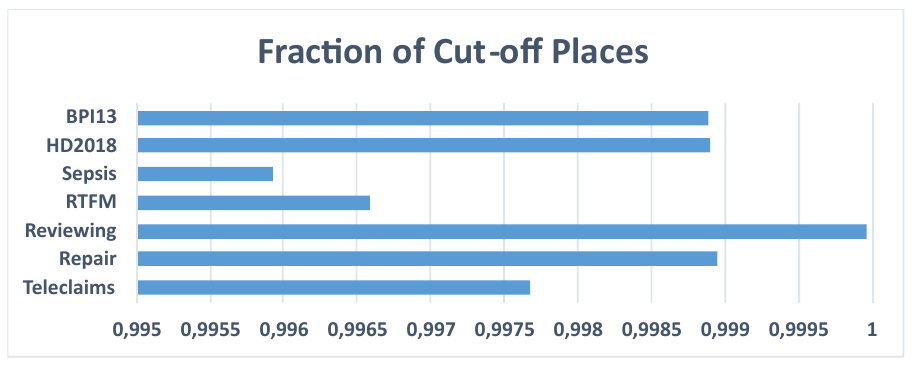
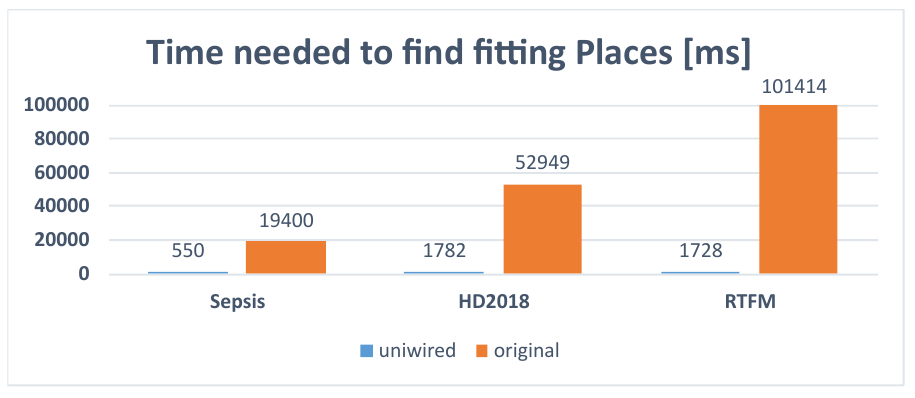
uniwired variant for various logs.
References
[1] Mannel, L., van der Aalst, W.: Finding complex process structures by exploiting the token-game. In: Application and Theory of Petri Nets and Concurrency. Springer Nature Switzerland AG (2019)
[2] van der Aalst, W.: Discovering the ”glue” connecting activities – exploiting monotonicity to learn places faster. In: It’s All About Coordination – Essays to Celebrate the Lifelong Scientific Achievements of Farhad Arbab (2018)
[3] Mannel, L., van der Aalst, W.: Finding uniwired Petri nets using eST-miner. In: Business Process Intelligence Workshop 2019. Springer (to appear)