Archive for April, 2019
Responsible Process Mining (RPM) – Confidentiality
This post is by Majid Rafiei, Scientific Assistant in the Process And Data Science group at RWTH Aachen University. Contact him via email for further inquiries.
To gain novel and valuable insights into the actual processes executed within a company, process mining provides a variety of powerful data-driven analyses techniques ranging from automatically discovering process models to detecting and predicting bottlenecks, and process deviations.
On the one hand, recent breakthroughs in process mining resulted in powerful techniques, encouraging organizations and business owners to improve their processes through process mining. On the other hand, there are great concerns about the use of highly sensitive event data. Within an organization, it often suffices that analysts only see the aggregated process mining results without being able to inspect individual cases, events, and persons. When analysis is outsourced also the results need to be encrypted to avoid confidentiality problems.
Surprisingly, little research has been done toward security methods and encryption techniques for process mining. The PADS team presented a novel approach that allows us to hide confidential information in a controlled manner while ensuring that the desired process mining results can still be obtained. In the following you can find a simplified version of our proposed framework.
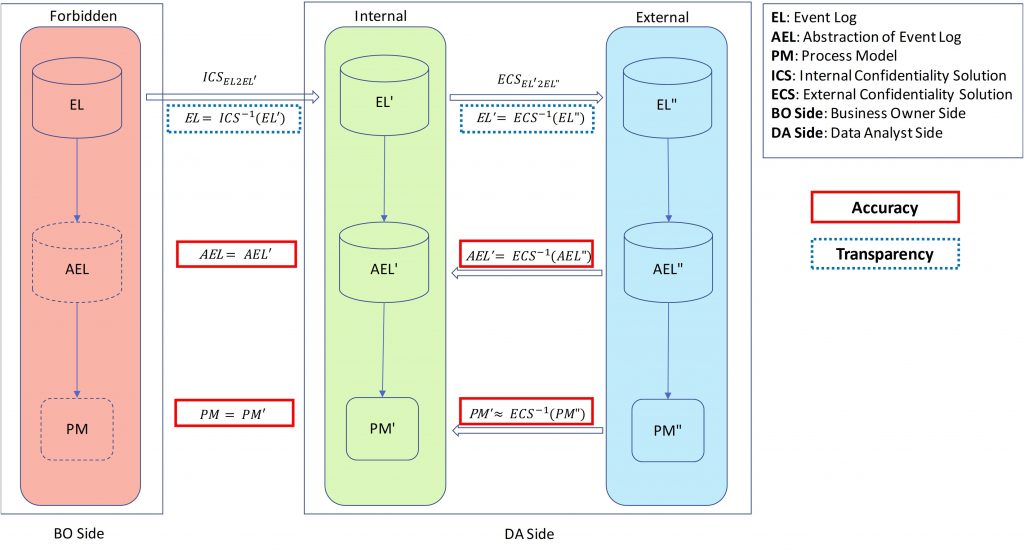
The paper which introduces this framework, and the connector method to preserve the sequence of activities securely has been selected as the best paper by SIMPDA 2018 (http://ceur-ws.org/Vol-2270/paper1.pdf). In this paper, we provide a sample solution for process discovery based on the above-mentioned framework.
Finding Complex Process-Structures by Exploiting the Token-game
This post is by Lisa Mannel, Scientific Assistant in the Process And Data Science group at RWTH Aachen University. Contact her via email for further inquiries.
Our paper „Finding Complex Process-Structures by Exploiting the Token-game“ has been accepted for publication by the 40th International Conference on Applications and Theory of Petri Nets and Concurrency.
In our paper we present a
novel approach to process discovery. In process discovery, the goal is to
find, for a given event log, the model describing the underlying process. While
process models can be represented in a variety of ways, in our paper we focus
on the representation by Petri nets. Using an approach inspired by
language-based regions, we start with a Petri net without any places, and then
insert the maximal set of places considered fitting with respect to the
behavior described by the log. Traversing and evaluating the whole set of all
possible places is not feasible, since their number is exponential in the
number of activities. Therefore, we propose a strategy to drastically prune
this search space to a small number of candidates, while still ensuring that
all fitting places are found. This allows us to derive complex model structures
that other discovery algorithms fail to discover. In contrast to traditional
region-based approaches this new technique can handle infrequent behavior and
therefore also noisy real-life event data. The drastic decrease of computation
time achieved by our pruning strategy, as well as our noise handling
capability, is demonstrated and evaluated by performing various experiments.
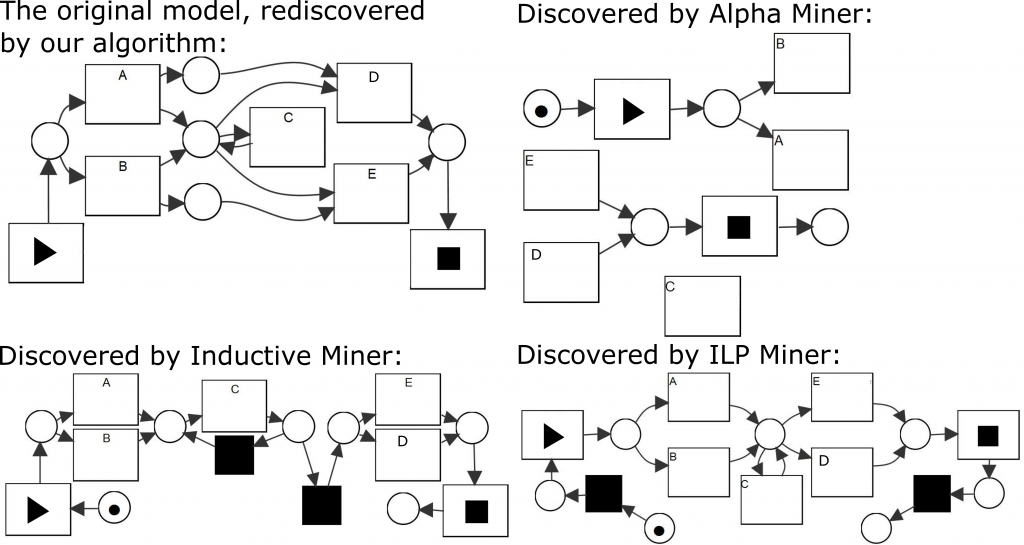
Figure 1: Consider the model shown in the upper left and assume L to be a complete log describing the behavior of this model. There exists a variety of discovery algorithms that are able to mine a process model based on L. As illustrated, the resulting Petri nets differ significantly between the algorithms. In particular, the places connecting A to D and B to E, which ensure that the first choice implies the second choice, are rarely discovered by existing algorithms.
You can download the full text here.
Applying Sequence Mining for outlier Detection in Process Mining
This post is by Mohammadreza Fani Sani, Scientific Assistant in the Process And Data Science group at RWTH Aachen University. Contact him via email for further inquiries.
The main aim of process mining is to increase the overall knowledge of business processes. This is mainly achieved by 1) process discovery, i.e. discovering a descriptive model of the underlying process, 2) conformance checking, i.e. checking whether the execution of the process conforms to a reference model and 3) enhancement, i.e. the overall improvement of the view of the process, typically by enhancing a process model. In each case the event data, stored during the execution of the process, is explicitly used to derive the corresponding results.
Many process mining algorithms assume that event data is stored correctly and completely describes the behavior of a process. However, real event data typically contains noisy and infrequent behaviour. The presence of outlier behaviour makes many process mining algorithms, in particular, process discovery algorithms, result in complex, incomprehensible and even inaccurate results. Therefore, to reduce these negative effects, in process mining projects, often a preprocessing step is applied that aims to remove outlier behaviour and keep good behaviour. Such preprocessing phase increases the quality and comprehensiveness of possible future analyses. Usually this step is done manually, which is costly and time-consuming and also needs business/domain knowledge of the data.

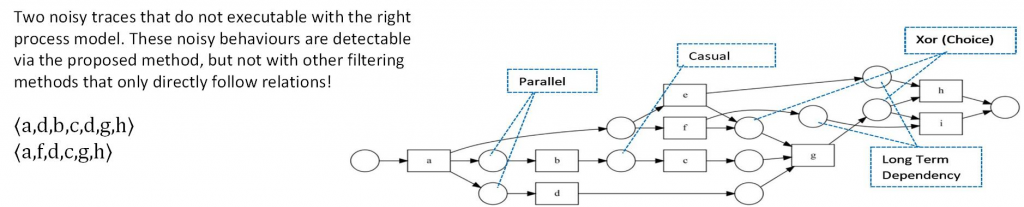
In this paper, we focus on improving process discovery results by applying an automated event data filtering, i.e., filtering the event log prior to apply any process discovery algorithm, without significant human interaction. Advantaging from sequential rules and patterns, long distance and indirect flow relation will be considered. As a consequence, the proposed filtering method is able to detect outlier behaviour even in event data with lots of concurrencies, and long-term dependency behaviour. The presence of this type of patterns is shown to be hampering the applicability of previous automated general purpose filtering techniques.
By using the ProM based extension of RapidMiner, i.e., RapidProM, we study the effectiveness of our approach, using synthetic and real event data. The results of our experiments show that our approach adequately identifies and removes outlier behaviour, and, as a consequence increases the overall quality of process discovery results. Additionally, we show that our proposed filtering method detects outlier behaviour better compared to existing event log filtering techniques for event data with heavy parallel and long-term dependency.