


Quelle: Freepik
Auf unserem FDM-Blog haben wir vor Kurzem über die Neuigkeiten bei Gaia-X und FAIR-Data Spaces berichtet. FAIR-Data Spaces ist ein cloud-basierter Datenraum für Wissenschaft und Wirtschaft, der mithilfe der Zusammenarbeit zwischen Gaia-X und der NFDI möglich gemacht und entwickelt wird.
Das Projekt
- konzipiert den Fahrplan für die Zusammenarbeit der beiden Initiativen,
- klärt ethische und rechtliche Rahmenbedingungen für den Datenaustausch zwischen Wissenschaft und Wirtschaft,
- erarbeitet gemeinsame technische Grundlagen
- und demonstriert die Nutzung von Gaia-X-Technologien für das Bereitstellen und Verwenden von Forschungsdaten entlang der FAIR-Prinzipien in verschiedenen Wissenschaftsdisziplinen und Branchen.
Doch wie gelangen lokale Daten in den cloud-basierten Datenraum? Um diesen Datenraum aus einer Anwenderansicht aufzuzeigen, möchten wir euch die Prozessschritte und den technischen Hintergrund näher erläutern.
Technischer Hintergrund
Das Projekt FAIR-Data Spaces wird in verschiedene Arbeitspakete unterteilt. Im Arbeitspaket AP4 geht es um die Demonstratoren, in denen gezeigt werden soll, dass die Infrastruktur, die in Teilen für NFDI4Ing aufgebaut wurde – also GitLab – in einer Hybrid-Cloud skaliert werden kann.
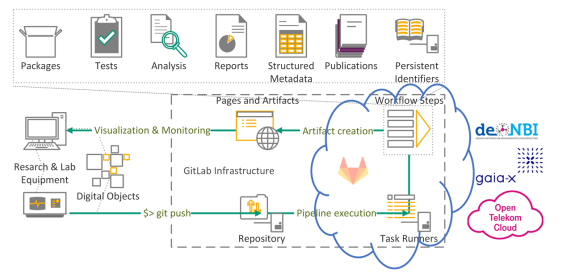
Qualitätssicherung im FDM als Workflow mit Git und GitLab. Quelle: Marius Politze
Der ganze Workflow läuft somit nicht auf der Hardware des IT Centers, sondern in einer Public-Cloud (blaue Wolke im Bild). Alles, was sich außerhalb der blauen Wolke befindet, existiert einmal. Die Task Runners und Workflow Steps innerhalb der blauen Wolke können mehrfach erzeugt werden und zwar nur dann, wenn sie gebraucht werden. Die Skalierung der Ressourcen kann somit gesteuert werden, sodass sie nur dann existieren, wenn sie nötig sind. So können die Ressourcen effizient eingesetzt werden, sodass keine teuren Server mehr benötigt werden, die zusätzlichen, physischen Platz einnehmen. Es handelt sich also um ein On-Demand-Angebot.
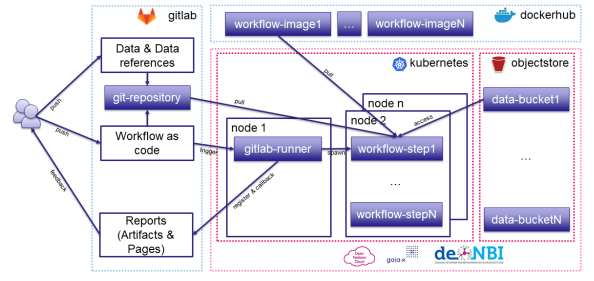
Architektur der technischen Infrastruktur im Demonstrator. Quelle: Marius Politze
Der Demonstrator kombiniert bestehende Technologien, die bei den beteiligten Serviceanbietern bereits aufgebaut wurden (blaue Umrandung in der Grafik). Dazu zählt der GitLab Service des IT Centers der RWTH und Dockerhub. Dockerhub ist ein öffentlicher Service, mit dem man Dokumente herunterladen kann. Für den Demonstrator wurde nun ein der Teil aufgebaut, der die Skalierungseigenschaften zeigen soll (pinke Umrandung in der Grafik). Dieser nutzt gemanagte Kubernetes-Instanzen der verschiedenen Public- und Community-Cloud, die am Projekt beteiligt sind (Open Telekom Cloud und deNBI Cloud). Die Kommunikation zwischen diesen Bestandteilen der entstandenen Hybrid-Cloud geschieht dann über die weit verbreiteten und standardisierte Protokolle HTTP und SSH/Git. Gesteuert wird das Ganze bei GitLab, was das Interface für die Nutzenden darstellt. Konkret bedeutet das, dass sich für die Nutzenden in der Handhabung nichts ändert, egal in welcher Cloud sich der pinke Kasten befindet. Somit können die Clouds im Hintergrund ausgetauscht werden, ohne dass sich der Workflow für die Nutzenden ändert.
Arbeitsschritte in GitLab
Die Nutzenden benötigen in erster Linie einen GitLab-Account. Den Zugriff darauf ermöglicht der Login mittels Shibboleth – also die Authentifizierung durch den Single Sign-On. Im Systemhintergrund arbeitet eine Kombination aus Dockerhub und Kubernetes, um den Datentransfer schnell und vereinfacht sicherzustellen. Die Nutzenden übertragen ihre Daten mithilfe von GitLab auf ein sogenanntes Git-Repository, indem sie die Aktion „push“ durchführen. Infolgedessen wird durch die Aktion „trigger“ eine GitLab-Runner-Instanz vom GitLab-Server benachrichtigt, welche die aktuellen Veränderungen in einen eigenen Arbeitsbereich überträgt. Mit der Aktion „run“ läuft der GitLab-Runner hierzu als Pod im Kubernetes-Cluster (kleinste Einheit einer Kubernetes-Anwendung). Durch die Aktion „spawn“ erzeugt der GitLab-Runner einen Workflow in Form eines Pods, welcher dann durch die Aktion „pull“ ein Image aus einer Registry lädt und von Kubernetes ausgeführt wird. Falls größere Datenmengen abgerufen werden sollen, wird dies durch einen externen Datenspeicher übernommen, da Git selbst dies nicht schafft. Dies geschieht mittels der Aktion „access“. Die Aktion „callback“ hat zur Folge, dass die Ergebnisse zurück an den GitLab-Server kommuniziert werden, nachdem der Workflow erfolgreich beendet wurde. Durch „feedback“ erhalten die Nutzenden schließlich ein Feedback der Ausführung z.B. in Form eines HTML5 Dashboards oder einer Berichtszusammenfassung.
Der Vorteil des Ganzen ist, dass die Nutzenden lediglich im Frontend von GitLab arbeiten und alle weiteren Prozesse im Systemhintergrund erfolgen.
Ausblick
Der Demonstrator wird im Projekt FAIR-Data Spaces weiterentwickelt und entsprechend der im Gaia-X Projekt erarbeiteten Spezifikationen beschrieben. So sollen langfristig Komponenten der Public-Cloud, wie z.B. Dockerhub austauschbar gemacht werden.
In Zukunft sollen Teile des Demonstrators für Verbesserung GitLab-Services an der RWTH genutzt werden und in die Serviceentwicklung einfließen.
Verantwortlich für die Inhalte dieses Beitrags ist Arlinda Ujkani.



