


Source: Freepik
On our FDM blog, we recently shared news about Gaia-X and FAIR-Data Spaces. FAIR-Data Spaces is a cloud-based data space for science and business, made possible and developed with the help of collaboration between Gaia-X and the NFDI.
The project
- designs the roadmap for collaboration between the two initiatives,
- clarifies ethical and legal frameworks for data exchange between science and industry,
- develops common technical principles
- and demonstrates the use of Gaia-X technologies for making research data available and usable along FAIR principles in different scientific disciplines and industries.
But how does local data get into the cloud-based data space? To show this data space from a user perspective, we would like to explain the process steps and the technical background in more detail.
Technical background
The FAIR-Data Spaces project is divided into different work packages. Work package AP4 is about the demonstrators, in which it will be shown that the infrastructure that was built in parts for NFDI4Ing – i.e. GitLab – can be scaled in a hybrid cloud.

Quality assurance in FDM as a workflow with Git and GitLab. Source: Marius Politze
The entire workflow thus does not run on the IT center’s hardware, but in a public cloud (blue cloud in the image). Everything outside the blue cloud exists once. The Task Runners and Workflow Steps within the blue cloud can be created multiple times and only when they are needed. The scaling of resources can thus be controlled so that they exist only when they are needed. This allows resources to be used efficiently, eliminating the need for expensive servers that take up additional, physical space. It is therefore an on-demand offering.
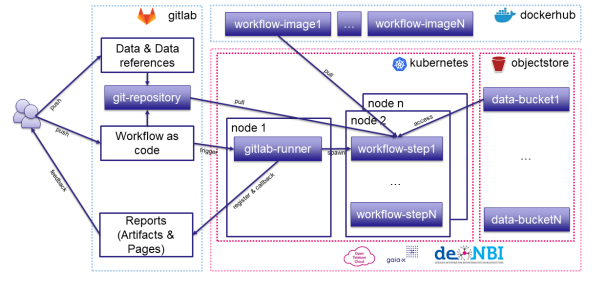
Architecture of the technical infrastructure in the demonstrator. Source: Marius Politze
The demonstrator combines existing technologies that have already been set up at the participating service providers (blue outline in the graphic). These include the GitLab service of the IT Center of RWTH and Dockerhub. Dockerhub is a public service that can be used to download documents. For the demonstrator, one of the parts has now been built to show the scaling properties (pink outline in the graphic). This uses managed Kubernetes instances from the various public and community clouds involved in the project (Open Telekom Cloud and deNBI Cloud). Communication between these components of the resulting hybrid cloud then takes place via the widely used and standardized HTTP and SSH/Git protocols. The whole thing is controlled at GitLab, which represents the interface for the users. In concrete terms, this means that nothing changes for the users in terms of handling, regardless of which cloud the pink box is located in. Thus, the clouds can be exchanged in the background without changing the workflow for the users.
Steps in GitLab
First and foremost, users need a GitLab account. Access to it is made possible by logging in using Shibboleth – i.e. authentication through single sign-on. A combination of Dockerhub and Kubernetes works in the system background to ensure fast and simplified data transfer. Users transfer their data to a so-called Git repository using GitLab by performing the “push” action. As a result, the “trigger” action notifies a GitLab runner instance from the GitLab server, which commits the current changes to its own workspace. With the “run” action, the GitLab runner runs as a pod in the Kubernetes cluster (smallest unit of a Kubernetes application) for this purpose. Using the “spawn” action, the GitLab runner creates a workflow in the form of a pod, which then uses the “pull” action to load an image from a registry and run it from Kubernetes. If larger amounts of data need to be retrieved, this is handled by an external data store, as Git itself cannot do this. This is done by means of the “access” action. The “callback” action results in the results being communicated back to the GitLab server after the workflow has been successfully completed. Finally, through “feedback” the users receive feedback of the execution e.g. in the form of an HTML5 dashboard or a report summary.
The advantage of all this is that users only work in the front-end of GitLab and all other processes take place in the system background.
Outlook
The demonstrator will be further developed in the FAIR-Data Spaces project and described according to the specifications developed in the Gaia-X project. In this way, components of the public cloud, such as Dockerhub, are to be made interchangeable in the long term.
In the future, parts of the demonstrator will be used for improving GitLab services at RWTH and will flow into service development.
Responsible for the content of this article is Arlinda Ujkani.



