
Applying Sequence Mining for outlier Detection in Process Mining
This post is by Mohammadreza Fani Sani, Scientific Assistant in the Process And Data Science group at RWTH Aachen University. Contact him via email for further inquiries.
The main aim of process mining is to increase the overall knowledge of business processes. This is mainly achieved by 1) process discovery, i.e. discovering a descriptive model of the underlying process, 2) conformance checking, i.e. checking whether the execution of the process conforms to a reference model and 3) enhancement, i.e. the overall improvement of the view of the process, typically by enhancing a process model. In each case the event data, stored during the execution of the process, is explicitly used to derive the corresponding results.
Many process mining algorithms assume that event data is stored correctly and completely describes the behavior of a process. However, real event data typically contains noisy and infrequent behaviour. The presence of outlier behaviour makes many process mining algorithms, in particular, process discovery algorithms, result in complex, incomprehensible and even inaccurate results. Therefore, to reduce these negative effects, in process mining projects, often a preprocessing step is applied that aims to remove outlier behaviour and keep good behaviour. Such preprocessing phase increases the quality and comprehensiveness of possible future analyses. Usually this step is done manually, which is costly and time-consuming and also needs business/domain knowledge of the data.

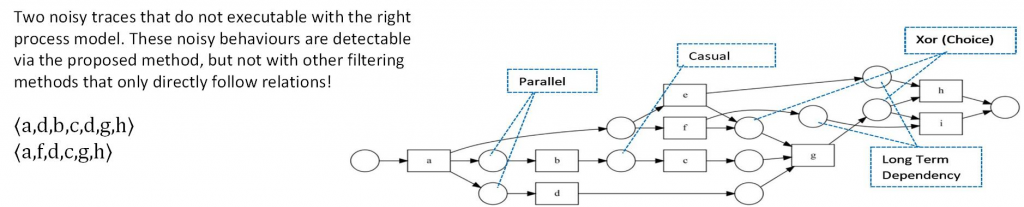
In this paper, we focus on improving process discovery results by applying an automated event data filtering, i.e., filtering the event log prior to apply any process discovery algorithm, without significant human interaction. Advantaging from sequential rules and patterns, long distance and indirect flow relation will be considered. As a consequence, the proposed filtering method is able to detect outlier behaviour even in event data with lots of concurrencies, and long-term dependency behaviour. The presence of this type of patterns is shown to be hampering the applicability of previous automated general purpose filtering techniques.
By using the ProM based extension of RapidMiner, i.e., RapidProM, we study the effectiveness of our approach, using synthetic and real event data. The results of our experiments show that our approach adequately identifies and removes outlier behaviour, and, as a consequence increases the overall quality of process discovery results. Additionally, we show that our proposed filtering method detects outlier behaviour better compared to existing event log filtering techniques for event data with heavy parallel and long-term dependency.
Prevention of “Melting Clocks” by Process Mining!
This post is by Elham Saberi, Scientific Assistant in the Process And Data Science group at RWTH Aachen University. Contact her via email for further inquiries.

Salvador Dalí, The Persistence of Memory, 1931. From Wikipedia
Process Mining studies the flow of work in an automated business process, from an initial to the final point, in order to find bottlenecks and parts in which time and money can be saved or processes can run more systematically and efficiently.
Conformance analysis, which is an essential procedure within process mining, represents how much the behavior described by a process model is in line with the behavior that is captured in an event log; additionally, performance analysis how much time is consumed in different parts of the executions. In particular, this type of analyses is useful to identify bottlenecks that are situations where the process execution slows down or in the worst case it is blocked.
“Time is Gold” so let’s get rid of bottlenecks!
Performance analysis is useful to detect bottlenecks or parts of process that are repeated several times and that leads to a longer trace execution.
When we deal with “real data”, we face with some common questions such as: How long does it take to execute a particular transition? Where are the “time holes” in the process? What are the necessary actions to speed up the process?
One of the ways to speed up the process is to change our global viewpoint to a more local and specific view that enables us to consider one individual place (with its pre-sets and post-sets) and concentrate on its behavior.
Global vs Local view – “Small is Beautiful” so think globally act locally!
There are numerous analysis tools (beside human brain!) which are perfect in doing local analysis, while global analysis generally provides less detailed information. That means, we have to compromise global and local analysis in order to have a balanced view on both. Local analysis, anyhow, is faster, to-the-point, with power to provide detailed diagnoses.
During a pilot research work at PADS RWTH a novel method was developed to align an event log and a Petri net containing visible unique transitions. This method provides a localized analysis by focusing on places in a process model. The method is faster in comparison to classic Conformance and Performance Analysis techniques like alignment-based and token-based replay; we called this new method IC-pairing alignment (IC stands for token Insertion and token Consumption).
In this localised analysis we deal with three scenarios: a place can be “fitting” (green places), “underfed” (blue places), or “overfed” (red places).
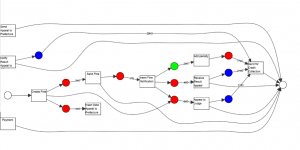
Colour-coded Petri net resulted from an IC-pairing alignment, which supports localized analysis.
This new type of alignment gives advantages to support process analysis more effectively, by detecting the lost time in process loops and the periods in the time interval in which the process has been most efficient (avoiding for example the re-opening of the whole process or the execution of additional activities). In addition, it is able to detect which constraints (places) in the process have problems, enabling the usage of repair techniques to improve the process model and making it more conform to the reality.
StarStar models: extract a process representation from databases without the need of a case notion
This post is by Alessandro Berti, Software Engineer in the Process And Data Science group at RWTH Aachen University. Contact him via email for further inquiries.
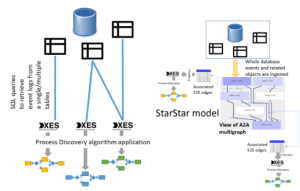
Comparison between classical ETL scenario (left) and ETL scenario with StarStar models (right).
In process mining projects, a vast amount of time is spent on the ETL phase, which is related to the extraction of the event logs and the process models. Process models can be discovered from event logs by applying a classic Process Mining technique (like the Inductive Miner). An event log is organized in cases and events, where a case groups events that are related to the same instance of the process. However, obtaining an event log from a database is a tricky process and requires the specification of a case notion, so a set of attributes/columns that group the events into cases. Specifying a case notion is often non-trivial:
- It requires a deep knowledge of the process(es) saved in the database
- It often requires to join several entities, making the extraction slow
Without expertise from both process and IT worlds, it seems difficult to extract an event log from a database. In the last years, some research has been done in order to simplify the extraction process, and we can cite some papers:
- Calvanese, Diego, et al. “Ontology-driven extraction of event logs from relational databases.” International Conference on Business Process Management. Springer, Cham, 2015. In this paper, a way to translate SPARQL queries, that are easier to express, into SQL queries is provided.
- Li, Guangming, Renata Medeiros de Carvalho, and Wil MP van der Aalst. “Automatic discovery of object-centric behavioral constraint models.” International Conference on Business Information Systems. Springer, Cham, 2017. In this paper, a modeling technique on-top of databases is presented, that is able to discover some interesting patterns for conformance checking application.
- de Murillas, Eduardo Gonzalez Lopez, et al. “Audit Trails in OpenSLEX: Paving the Road for Process Mining in Healthcare.” International Conference on Information Technology in Bio-and Medical Informatics. Springer, Cham, 2017. In this paper, a meta-model where database events can be inserted is presented. This meta-model could be queried using SQL language and the complexity of event log retrieval is decreased.
The PADS team developed StarStar models, that are a novel way to represent event data on top of relational databases. The main view provided by StarStar models is the A2A (activities) multigraph, in which activities can be connected by several edges.
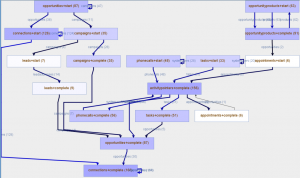
A2A multigraph of the StarStar model extracted from a Dynamics CRM installation.
An edge in the A2A multigraph is associated to a class perspective, and is inferred observing directly-follows relationships between events in the perspective of some object belonging to the given class. StarStar models provide also a drill-down functionality where, given a class perspective, a classic event log to use with mainstream process mining techniques can be obtained.
Classic event logs and process models can be obtained through drill-down in a StarStar model.
StarStar models seems to be very promising for process visualization, since the edge can be annotated by the frequency or the performance (along with the class perspective for which the edge was detected).
New Process Mining Conference (ICPM 2019)
One of three conferences taking place in Aachen in June 2019
The first IEEE International Conference on Process Mining (ICPM) will take place in Aachen (Germany), 24-28 June 2019. ICPM will be co-located with the 40th International Conference on Application and Theory of Petri Nets and Concurrency (Petri Nets 2019), and the 19th IEEE International Conference on Application of Concurrency to System Design (ACSD 2019). The three events will take place in the conference area of the Tivoli football stadium and are organized by the Process and Data Science (PADS) group led by Wil van der Aalst at RWTH Aachen University. Interestingly, the first BPM conference was also co-located with the Petri Nets conference in 2003. Hence, this could be the start of a very successful conference series.

The objective of ICPM 2019 is to explore and exchange knowledge in this field through scientific talks, industry discussions, contests, technical tutorials and panels. The conference covers all aspects of process mining research and practice, including theory, algorithmic challenges, applications and the connection with other fields. The event unifies activities done within the context of the IEEE Task Force on Process Mining. The task force was established in 2009 to promote process mining activities and to create awareness. Over 70 organizations are supporting the IEEE Task Force on Process Mining. Wil van der Aalst is general chair, and Josep Carmona, Mieke Jans, and Marcello La Rosa lead an international program committee composed of 45 process mining experts. See http://icpmconference.org/ for more information about ICPM 2019.

The developments in research and teaching (see the success of the process mining MOOC) have been mirrored by a strong industry uptake, mainly in Europe but now also spreading to other continents like to US and Asia. For example, Gartner released a market guide on process mining in April this year, describing the various categories of process mining techniques and how these are supported by various software vendors, while MarketsAndMarkets has predicted that the process analytics market will be worth USD 1,422 million by 2023, with conformance checking (a category of process mining techniques) expected to be the fastest-growing segment of process analytics market during the forecast period. This further supports the need for a dedicated conference and meeting place.
Another special feature of the event is the celebration of 40 years of Petri net conferences with special guest speakers reflecting on the historical role of Petri’s work.
Welcome to our PADS Blog!
Our research group aims to progress the state-of-the-art in Process and Data Science, this with a particular focus on process mining. Therefore, we seek innovative ways of information sharing, and this new blog is one of them (next to tweets @pads_rwth and news items on our home page). The goal is to showcase the work done in the group in an informal manner. Blog posts will report on internal presentations, new research results, new activities, and other exciting developments. The group was founded recently (January 2018), but already approx. 20 group members joined, and many exciting activities have been started. For example, we are involved in the approved Cluster of Excellence – Internet of Production (IoP) where we collaborate with groups working on production systems. We also closely collaborate with Uniklinik RWTH Aachen on process mining in healthcare. In 2019, we will organize three conferences: the first International Conference on Process Mining (ICPM 2019), the 40th annual Conference on Application and Theory of Petri Nets and Concurrency (ATPN2019), and the 19th International Conference on Application of Concurrency to System Design (ACSD 2019). In short: “Data Science in Action” and Aachen is where the action is.

Picture: Alexander von Humboldt professorship awarded to prof. Wil van der Aalst by the Federal Minister Anja Karliczek in May 2018.
These are exciting times for a research group working on the interface between process science and data science. The interest in process mining is booming, and many of our research results are directly applied in industry. At the same, we are working on foundational problems related to process discovery, conformance checking, and performance analysis. With Fraunhofer FIT, we work on automated, data-driven process improvement and our dream is to provide tools that suggest process redesigns based on domain knowledge and event data. Topics such as Robotic Process Automation (RPA), Case Management (CM), Business Process Management (BPM) can also greatly benefit from process mining. The work done by the chair has led to a new breed of analytics tools. Currently, there are about 25 organizations providing process mining tools on a commercial basis. At the same time, we feel responsible for developing data science techniques protecting people from irresponsible uses of event data. Topics such as fairness, accuracy, confidentiality, and transparency need to be addressed urgently. Therefore, our research on responsible process mining nicely completes the research portfolio of our group. The Alexander von Humboldt professorship awarded to me by the Federal Minister Anja Karliczek in May 2018, enables us to attract young talent to come to Aachen to work on these topics. If you are interested in joining us, please let us know!
We hope that you enjoy the subsequent blog posts!
Wil van der Aalst