

Quelle: Eigene Darstellung
Heute nehmen wir euch mit auf eine Reise, die bei eurer Anfrage im Browser beginnt und bei der finalen Darstellung der Webseite aufhört.
Was passiert eigentlich im Hintergrund wenn ihr eine Webseite aufruft? Wie arbeitet ein Browser? Was ist ein DNS und was hat ein Port damit zu tun?
Back to Basic
Computer oder Prozessoren arbeiten mit einem binären Zahlensystem und verstehen grundsätzlich nur 0 und 1. Kombiniert man diese jedoch miteinander, werden daraus weitere Zahlen gebildet. So entstehen die sogenannten IP-Adressen, welche jedem Computer oder Gerät mit Internetzugang zugeordnet werden. IP-Adressen sind wie eine Art Telefonnummer, die einer bestimmten Person zugeordnet ist. Die meisten von uns Menschen können sich besser Wörter oder Sätze anstatt Zahlen merken, weshalb auch Computer an vielen Stellen nicht mit Zahlen, sondern mit Wörtern arbeiten. Normalerweise müssten wir in die URL-Zeile eines Browsers die IP-Adresse eines Webservers eingeben, um diesen zu erreichen und die Webseite zu öffnen. Damit wir das nicht tun müssen, gibt es das DNS.
Das DNS – Domain Name System
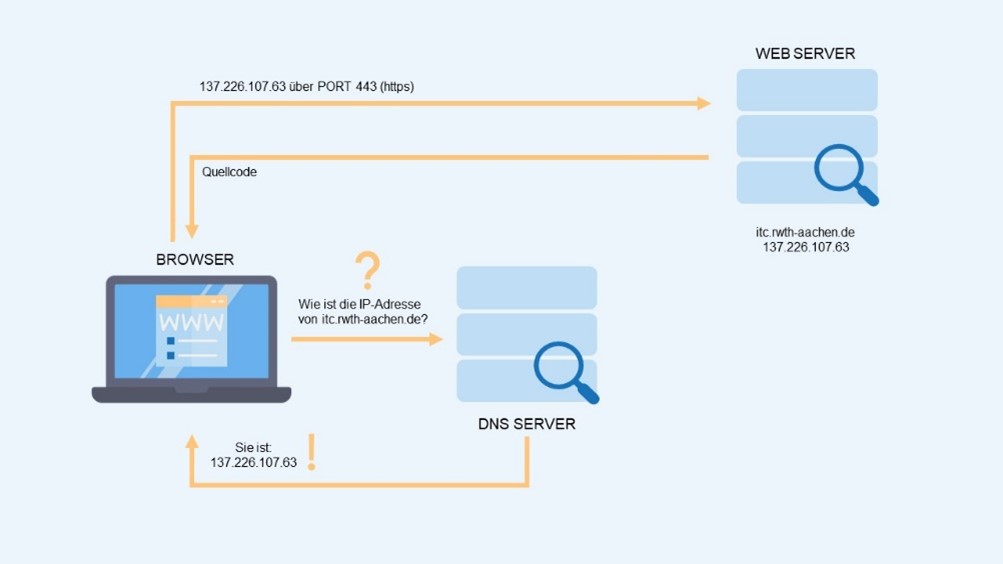
Damit wir einfach Wörter in den Browser eingeben können, gibt es das sogenannte DNS (Domain Name System). Das DNS agiert in diesem Moment als Übersetzer, welcher IP-Adressen in Wörter, genauer genommen die Domain umwandelt. Dies funktioniert genauso umgekehrt. Die Domains können also auch in IP-Adressen umgewandelt werden. Ihr könnt euch das DNS aber auch als ein riesengroßes Telefonbuch vorstellen. Wird eine Anfrage für eine Domain gestellt, wird in dem Telefonbuch nachgeschlagen, wie die IP-Adresse des Servers lautet, auf dem die Webseite gespeichert ist.
Doch wie funktioniert denn jetzt ein Browser?
Stellt euch nun mit diesem Hintergrundwissen vor, ihr sitzt vor eurem Computer und tippt eine Domain in die URL-Zeile eures Browsers ein.
Was macht euer Browser nun?
Er stellt eine Anfrage an einen DNS-Server. Euer Browser weiß nämlich auf Anhieb nicht, auf welchem Server die Webseite verfügbar ist. Was der Browser aber kennt, ist die Adresse des DNS-Servers. Diesen DNS-Server fragt er jetzt: Welchen Webserver muss ich ansprechen, um die entsprechende Webseite zu finden. Der DNS-Server sucht nun in seiner riesengroßen Datenbank und liefert dem Browser eine IP-Adresse.
Im nächsten Schritt stellt euer Browser basierend auf der IP-Adresse, die er erhalten hat, eine neue Anfrage an den Webserver. Diese ergänzt er aber um einen Port. In diesem Fall ist das der Port 443. Durch den Port 443 weiß der Webserver, dass es sich um eine sogenannte „https“-Anfrage handelt.
Die richtigen Ports und Quellcodes
Ihr alle kennt „https“ aus der URL. Bei „https“ handelt es sich um ein Protokoll zur Darstellung von Webseiten. Ports könnt ihr euch vorstellen wie Postkästen in einem Mehrfamilienhaus. Wie jeder Haushalt seinen eigenen Briefkasten hat, so hat auch jedes Protokoll seinen eigenen Port. Port ist ein Begriff aus dem Englischen und heißt auf Deutsch Anschluss oder Durchlass. Über einen Port gelangen Informationen von eurem Computer ins Internet oder vom Internet wieder an euren Computer zurück.
Alle Webseiten kommunizieren mit dem Internet, um Ihnen die Inhalte anzeigen zu können. Sie bekommen also von dem Internet verschiedene Daten an Ihren Computer gesendet. Durch die Ports weiß der Computer, welche Daten zu welcher Anwendung, also Webseite gehört.
Jeder Port hat eine andere Nummer. Die Daten, die vom Internet bei eurem Computer ankommen, enthalten also alle eine Portnummer. So wird der Port 443 für Anfragen für Webseiten verwendet. Wollen wir also die Webseite itc.rwth-aachen.de erreichen, senden wir die Anfrage über Port 443. Die Anfrage hat das Ziel, dass die Webseite angezeigt wird. Wurde die Anfrage gestellt sucht der Webserver alle Informationen zusammen, um die Webseite anzeigen zu können. Er sucht nach Informationen, Bildern sowie Texten und baut damit einen Quellcode zusammen, welchen er anschließend an den Browser zurückschickt.
Der Browser erhält mit dem Quellcode aber erst mal nur eine Textdatei. In dieser stehen die Informationen, die er zum Anzeigen der Webseite braucht. Beispielsweise wie der Seitentitel lautet, ob ein PDF verlinkt ist oder die URL zu einem Bild.
Der Browser fängt dann an, sich von oben nach unten durch den Quellcode zu arbeiten. Beim Durcharbeiten der Datei fällt dem Browser beispielsweise auf, dass ihm eine Schriftart fehlt oder Bilder. Diese Ressourcen liegen aber auf anderen Webserver im Internet, sodass der Browser weitere DNS-Anfragen stellen muss. Für jede einzelne Ressource werden weitere DNS-Anfragen gestellt. Das Spiel geht also von vorne los. Je nachdem wie viele Elemente die Webseite hat und der Browser sich diese Informationen zusammensuchen muss, desto länger ist die Ladezeit der Seite.
Endlich – die fertige Seite
Parallel zum Abfragen dieser Daten auf anderen Servern fängt der Browser parallel an die Seite zu „rendern“. Das bedeutet darzustellen. All das oben genannte geschieht üblicherweise innerhalb weniger Sekunden. Hat der Browser alle Informationen zusammen, wird die Seite final geladen und euch vollständig angezeigt.
Verantwortlich für die Inhalte dieses Beitrags ist Janin Vreydal.



