
This post has been authored by Marco Pegoraro.
Introduction
Process mining bridges the gap between data science and business process management by extracting insights from event logs—records of activities captured by modern information systems. Traditional discovery techniques assume event data is precise and accurately recorded, but in many real-world settings, logs contain explicit uncertainty, such as ambiguous timestamps or multiple possible activity labels. In [1] we introduce the concept of uncertain event logs, aiming to extend conformance and discovery algorithms to handle data imprecision without discarding valuable information.
Why Uncertainty Matters
In practice, data imperfections arise from manual entries, system delays, or coarse timestamp granularity. For example, two activities may share the same recorded time unit, making their order unclear, or a sensor might register one of several possible activity types. Ignoring such uncertainties can lead to misleading models or force analysts to prune important cases. By explicitly modeling uncertainty, process mining can produce more faithful representations of actual behavior, highlighting both certain and ambiguous aspects of the process.
A Taxonomy of Uncertain Event Logs
Uncertain event data is classified into two main categories:
- Strong uncertainty, where the log lists all possible values for an attribute without probabilities (e.g., an event’s activity label is either “Approve” or “Reject”). Table 1 shows an example of strongly uncertain trace.
- Weak uncertainty, where a probability distribution over possible values is provided.
Logs displaying, respectively, strong and weak uncertainty on activity labels are also known in literature as stochastically-known an stochastically-unkown logs [2].
Their focus is on a simplified subset of uncertain behavior that encompasses strong uncertainty on control flow attributes: activity names, timestamps (expressed as intervals), and indeterminate events whose presence is optional. This clear taxonomy guides the design of algorithms that handle varying levels of data confidence.
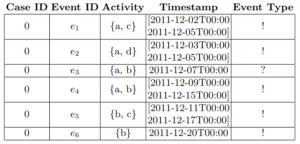
Table 1: An example of strongly uncertain trace. Possible activity labels for events are enclosed in curly braces. Uncertain timestamps are represented by time intervals. Event e3 is indeterminate: it might have been recorded without occurring.
Capturing Uncertain Behavior with Graphs
In [3], we describe an extension of the Inductive Miner family of algorithms able to ingest strongly uncertain event logs.
At the core of the proposed approach is the uncertain directly-follows graph (UDFG)—an extension of the classic directly-follows graph that retains information about ambiguity. Instead of a single directed edge from activity labels A to B representing that B directly follows A, the UDFG records:
- Certain edges, where all traces support the relation A→B.
- Possible edges, where some traces may support A→B under certain resolutions of uncertainty.
The nodes are also enriched with the same parameters, in relation to the certain executions of a single activity, and the possible executions of a single activity. As a result, the UDFG succinctly encodes where the process behavior (as illustrated by the data) is definitive, and where alternate real-life scenarios exist.
Discovering Models from Uncertain Data
To transform the UDFG into an interpretable process model, we apply inductive mining—a robust technique that produces block-structured models free of spurious behavior. The workflow is:
- Construct the UDFG from the uncertain log, marking edges as certain or possible.
- Filter edges with a specific set/configuration of parameters, which induce inclusion/exclusion criteria for uncertain aspects of the input log.
- Apply inductive mining: we obtain a process tree from the filtered UDFG, through the Inductive Miner directly-follows algorithm [4].
- Merge results to highlight which parts of the model are supported by all possible interpretations and which depend on resolving uncertainty.
This dual-mining strategy yields two related models: one conservative and one inclusive, giving analysts a spectrum of process variants to consider.
Experimental Insights
In their experiments on both synthetic and real-world logs, we show that:
- The UDFG can be easily defined and obtained even for large logs with complex uncertainty patterns.
- Models derived from a “traditional” (certain) DFG avoid underfitting noise but may miss legitimate behavior expressed by uncertainty.
- Inclusive models reveal potential flows that warrant further data cleaning or validation.
Overall, the approach offers filtering mechanisms that can balance precision and fitness, allowing process mining specialists to control how conservatively or aggressively they treat uncertain data.
Conclusion and Future Directions
By embracing rather than discarding uncertainty, this work advances process discovery to better reflect real-life data quality issues. The proposed UDFG and dual inductive mining deliver models that clearly distinguish between guaranteed and hypothetical behavior. The authors highlight several avenues for future research, including:
- Defining quantitative metrics to compare uncertain models.
- Extending the approach to weak uncertainty with probability distributions.
- Incorporating uncertainty in case identifiers and other perspectives beyond control flow.
For practitioners, this paper offers practical guidance on modeling and visualizing ambiguous traces, ensuring that insights remain grounded in the realities of data collection.
References
- Pegoraro, Marco, and Wil M.P. van der Aalst. “Mining uncertain event data in process mining.” In 2019 International Conference on Process Mining (ICPM), pp. 89-96. IEEE, 2019.
- Bogdanov, Eli, Izack Cohen, and Avigdor Gal. “Conformance checking over stochastically known logs.” In International Conference on Business Process Management, pp. 105-119. Cham: Springer International Publishing, 2022.
- Pegoraro, Marco, Merih Seran Uysal, and Wil M.P. van der Aalst. “Discovering process models from uncertain event data.” In International Conference on Business Process Management, pp. 238-249. Cham: Springer International Publishing, 2019.
-
Leemans, Sander J.J., Dirk Fahland, and Wil M.P. van der Aalst. “Scalable process discovery and conformance checking.” Software & Systems Modeling 17 (2018): 599-631.
