Archive for September, 2025
Federated Directly-Follows Graph Discovery
by Christian Rennert based on a paper by Christian Rennert, Julian Albers, Sander Leemans, and Wil van der Aalst
Federated process mining focuses on the problem of leveraging process mining methods for inter-organizational use cases while guaranteeing and preserving privacy of the individual event data. However, the desired outcomes should be as close or even identical to the outcomes as if all data was in one place to optimize the expressiveness of the obtained results. One paper that helps this aim is: “Your Secret Is Safe With Me: Federated Directly-Follows Graph Discovery” by Christian Rennert, Julian Albers, Sander Leemans, and Wil van der Aalst and that is going to be presented at ICPM 2025. In this paper, we suggest how to discover directly-follows graphs (DFGs) with homomorphic encryption to allow for a privacy-preserving, federated discovery between collaborating organizations. In the following, we outline the paper.
Key Concepts
- The Problem: In many cases, business processes span multiple organizations. For example, a patient’s treatment might involve a hospital and a general practitioner. However, while case IDs may already agree by default, i.e., due to the insurance ID, the hospitals or general practitioners might not know if they were both visited by any patient. Further, organizations may be unwilling to share their process data due to commercial sensitivity or privacy laws.
- The Goal: Extending the toolkit of federated process mining using a solution that leverages multi-party computation and homomorphic encryption. Thus, allowing organizations to perform inter-organizational analyses without sharing their private data in a readable form. The paper’s specific aim is to allow two organizations to create a directly-follows graph (DFG) of their combined process without revealing their individual event logs.
- The Solution: The paper introduces a new protocol that uses fully homomorphic encryption (FHE) to discover a DFG while keeping timestamps and activities secret. Unlike previous approaches, this protocol does not require a trusted third party, a majority of honest organizations, or prior knowledge of the workflow. It does, however, require organizations to have a common case ID (like a social security number) and to pre-negotiate which activities will be included in the final DFG.
The Two Protocols
The paper presents two main protocols, a highly secure one and a more efficient one, both of which utilize the same core subroutine for constructing DFG edges.
- Brute-Force Protocol (BF): This is a highly secure but computationally expensive approach. One organization encrypts its event sequence and sends it to the other organization, which then computes the encrypted DFG edges. The other organization shuffles the encrypted edges and sends them back to the first organization for decryption.
- Trace-Based Protocol (TB): This is a less costly but also less secure method. It reveals some information, specifically common case IDs and the number of events in each case. By making common case IDs transparent, it allows for faster computations. This protocol is considered to eliminate the need for trust in collaborating organizations, as they cannot corrupt computations.
The paper concludes that both protocols are feasible and correct, though the BF protocol is the only known one to also cover privacy of case IDs for DFG discovery.
You can find the full paper at the following link: https://leemans.ch/publications/papers/icpm2025rennert.pdf.
Configuring Large Reasoning Models using Process Mining: A Benchmark and a Case Study
This post has been authored by Dr. Alessandro Berti
In the ever-evolving landscape of artificial intelligence, Large Language Models (LLMs) have become indispensable tools for tackling complex tasks, but when it comes to scientific reasoning, transparency and logical rigor are paramount. Enter Large Reasoning Models (LRMs), a specialized breed of LLMs trained to explicitly articulate their chain-of-thought, making them ideal for domains like process mining where the journey to an answer is as critical as the destination itself. A recent paper titled “Configuring Large Reasoning Models using Process Mining: A Benchmark and a Case Study” by Alessandro Berti, Humam Kourani, Gyunam Park, and Wil M.P. van der Aalst dives deep into this intersection, proposing innovative ways to evaluate and fine-tune LRMs using process mining techniques. This work not only bridges AI and process mining but also offers practical tools for enhancing model performance in scientific applications.
Link to the paper (pre-print): https://www.techrxiv.org/doi/full/10.36227/techrxiv.174837580.06694064/v1
The paper kicks off by highlighting the limitations of standard LLMs in scientific contexts, where verifiable reasoning is essential. LRMs address this by producing textual “reasoning traces” that outline their step-by-step logic. However, evaluating these traces has been underexplored until now. Drawing from the PM-LLM-Benchmark v2.0, a comprehensive dataset of LLM responses to process mining prompts, the authors introduce a pipeline to dissect these traces. The process begins with extracting individual reasoning steps from the raw outputs, classifying each by type, such as Pattern Recognition for spotting anomalies, Deductive Reasoning for logical derivations, Inductive Reasoning for generalizing from data, Abductive Reasoning for inferring explanations, Hypothesis Generation for proposing testable ideas, Validation for verifying steps, Backtracking for revising errors, Ethical or Moral Reasoning for considering fairness, Counterfactual Reasoning for exploring alternatives, and Heuristic Reasoning for applying practical rules. Each step is further labeled by its effect on the overall reasoning: positive (advancing correctness), indifferent (neutral or redundant), or negative (introducing errors). This structured approach transforms unstructured text into analyzable JSON objects, enabling a nuanced assessment beyond mere output accuracy.
Building on this foundation, the authors extend the existing benchmark into PMLRM-Bench, which evaluates LRMs on both answer correctness and reasoning robustness. Using a composite score that rewards positive steps and correct conclusions while penalizing errors and inefficiencies, they test various models, revealing intriguing patterns. Top performers, like Grok-3-thinking-20250221 and Qwen-QwQ-32B, excel with high proportions of positive-effect steps, particularly in deductive and hypothesis-driven reasoning, correlating strongly with overall task success. Weaker models, conversely, suffer from over-reliance on speculative types without adequate validation, leading to more negative effects. The benchmark also breaks down performance by process mining categories, showing that tasks like conformance checking favor deductive reasoning, while hypothesis generation benefits from exploratory types. A validation check using multiple LLMs as judges confirms the classification’s reliability, with over 82% agreement.
The real-world applicability shines in the case study on the QwQ-32B model, a 32-billion-parameter LRM refined for complex reasoning. By tweaking system prompts to emphasize or suppress specific reasoning types—such as boosting Hypothesis Generation or Ethical Reasoning—the authors demonstrate targeted improvements. For instance, increasing Hypothesis Generation enhanced scores in exploratory tasks like contextual understanding and conformance checking, pushing the overall benchmark score to 37.1 from the baseline’s 36.9. Reducing it, however, hampered performance in hypothesis-heavy categories. Adjustments to Ethical Reasoning showed mixed results, improving reasoning quality in fairness tasks but sometimes overcomplicating others without net gains. These experiments underscore the trade-offs in LRM configuration, proving that process mining-inspired analysis can guide precise tweaks for domain-specific optimization.
In conclusion, this paper paves the way for more interpretable and configurable AI in scientific fields. By treating reasoning traces as process logs, it applies process mining to uncover strengths, weaknesses, and optimization paths in LRMs. While reliant on accurate LLM-based classification and potentially overlooking latent model intricacies, the framework’s generalizability extends beyond process mining to any reasoning-intensive domain. Future enhancements could incorporate ensemble judging or human oversight to refine accuracy. For process mining enthusiasts, this work is a call to action: leveraging benchmarks like PMLRM-Bench could unlock new levels of AI-assisted discovery, making complex analyses more reliable and efficient. The full resources, including the benchmark and case study data, are available on GitHub, inviting further exploration and collaboration.
Visualizing Object-Centric Petri Nets
by Lukas Liss based on a paper by Tobias Brachmann, István Koren, Lukas Liss, and Wil van der Aalst
Process mining has become essential for understanding how organizations actually work, but there’s been a fundamental limitation: traditional approaches focus on single entities like “orders” or “customers,” missing the bigger picture of how multiple entities interact in real business processes.
The Challenge: Beyond Single-Case Thinking
Imagine analyzing an e-commerce process. Traditional process mining might follow individual orders from creation to delivery. However, real business processes are more complex – orders involve products, customers, warehouses, and shipping providers, all interacting in intricate ways. A single order might involve multiple products, each with different suppliers and delivery requirements. This complexity gets lost when we only look at one type of entity at a time.
This is where Object-Centric Process Mining (OCPM) comes in. Instead of following just orders or just customers, OCPM tracks all the different types of objects and their interactions simultaneously. An established process model for this are Object-Centric Petri Nets (OCPNs) – a more sophisticated way to model processes that can handle multiple interacting lifecycles.
The Visualization Problem
Here’s where things get tricky: these richer, more realistic process models are much harder to visualize clearly. Traditional Petri net visualization tools weren’t designed for this complexity. When you have multiple object types, variable connections between them, and complex interdependencies, standard graph layout algorithms produce cluttered, hard-to-interpret diagrams.
Think of it like trying to use a city road map to understand a complex subway system with multiple interconnected lines – the visualization just wasn’t designed for that level of complexity.
Our Solution: A Tailored Visualization Approach
Our research addresses this gap by developing a specialized layout algorithm specifically designed for OCPNs. Rather than forcing these complex models into generic graph visualization tools, we created an approach that understands and leverages the unique characteristics of object-centric processes.
Key Innovations
- Smart Quality Metrics We defined six quality metrics that guide the visualization:
- Traditional graph aesthetics (minimizing edge crossings, reducing edge length)
- Object-centric considerations (grouping related object types, maintaining clear flow direction)
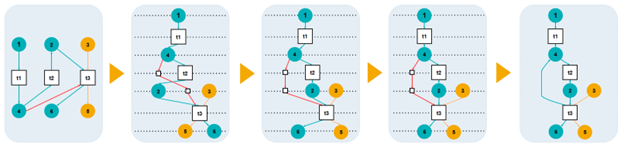
- Adapted Sugiyama Algorithm We extended the well-known Sugiyama framework – a hierarchical graph layout method – to handle object-centric specifics:
- Cycle Breaking: Handling loops in process flows
- Layer Assignment: Organizing elements into logical hierarchical levels
- Vertex Ordering: Arranging elements within each level to minimize visual confusion
- Positioning & Routing: Computing final coordinates and drawing clean connections
- Object-Type Awareness Unlike generic tools, our algorithm actively groups places (representing object states) by their object type, making it easier to understand how different business entities flow through the process.
Real-World Impact
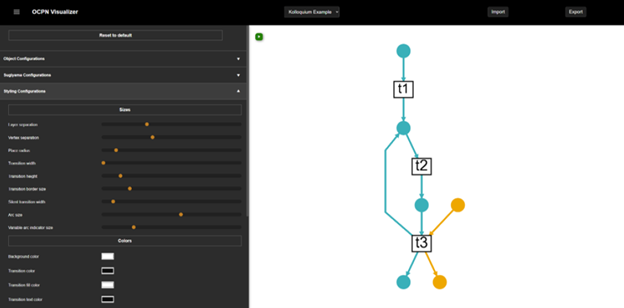
We built this into a practical tool called the OCPN Visualizer – a web-based application that researchers and practitioners can use. The tool includes:
- Interactive configuration options for customizing layouts
- Real-time visualization updates as you adjust parameters
- Export capabilities for integration into other workflows
- A reusable JavaScript library for developers
Why This Matters
This work addresses a real bottleneck in object-centric process mining adoption. As organizations increasingly recognize the value of understanding their complex, interconnected processes, they need tools that can make this complexity manageable and interpretable.
The research contributes to the field in three ways:
- Theoretical Foundation: Quality metrics that combine graph aesthetics with domain-specific needs
- Algorithmic Innovation: A layout algorithm tailored to object-centric characteristics
- Practical Tools: Open-source implementations that others can use and build upon
Looking Forward
While our approach works well for small to medium-sized models, there’s still room for improvement with very large, complex process models. Future work could explore more advanced edge routing techniques, better handling of dense interconnections, and more sophisticated filtering options for exploring large models.
The broader impact extends beyond just visualization – by making object-centric process models more interpretable, this work helps bridge the gap between advanced process mining techniques and their practical application in real organizations.
Resources
Find the source code, a link to the web-based tool, and example input data on Github: https://github.com/rwth-pads/ocpn-visualizer