

Schlagwort: ‘NFDI’
Nachbericht der NFDI-Konferenz 2020
Am 8. Und 9. Juli 2020 fand die zweite NFDI-Konferenz als Online-Seminar statt.
Die Konferenz
Auf der diesjährigen NFDI-Konferenz ging es darum, die Vertreterinnen und Vertreter von geplanten Konsortien über das Konzept und die übergreifenden Ziele der NFDI sowie über die Eckpunkte der Antragstellung durch die DFG zu informieren.
Außerdem konnten sich die zur Förderung vorgeschlagenen und die geplanten Konsortien untereinander vorstellen und austauschen sowie den neuen NFDI-Direktor, Professor Dr. York Sure-Vetter, kennenlernen. Das Direktorat wird zukünftig die Selbstorganisation und Vernetzung der Konsortien zu konsortienübergreifenden Diensten, zu fachnahen oder datenähnlichen Angeboten und bei weiteren Fragen, unterstützen. (Quelle) Weiterlesen »
Nationale Forschungsdateninfrastruktur: Website NFDI.de online
Der Aufbau der Nationalen Forschungsdateninfrastruktur (NFDI) nimmt nach und nach immer mehr Gestalt an. Nachdem Ende Februar Prof. York Sure-Vetter von den Vorsitzenden der Gemeinsamen Wissenschaftskonferenz (GWK) als Direktor der NFDI eingesetzt wurde, ist im Mai die offizielle Homepage der NFDI online gegangen.
Immer auf dem neusten Stand
Die neue Website ist gut überschaubar und wird laufend aktualisiert.
Neben den aktuellen Entwicklungen und bevorstehenden Terminen findet man dort auch allgemeine Informationen über die Entstehung, Struktur und Aufbau der NFDI.
Das eingesetzte Direktorat der NFDI stellt sich unter der gleichnamigen Registerkarte vor.
Unter dem Reiter „Konsortien“ sind die antragstellenden Konsortien der ersten Förderungsrunde aufgelistet und die entsprechenden Websites für weitere Informationen verlinkt.
Die nächsten Schritte
Mit der Veröffentlichung der zweiten Ausschreibung zur Förderung von Konsortien am 25. Mai 2020 wurde der Startschuss für die nächste Runde gegeben. Die antragsstellenden Konsortien werden wir auch diesmal wieder im Rahmen einer Reihe auf diesem Blog vorstellen.
Momentan befindet sich die NFDI in der spannenden Phase. Am 26. Juni 2020 wurde die Förderentscheidung der GWK über die Anträge der ersten Runde verkündet.
Gestern und heute (08. & 09.07.20) fand außerdem die zweite NFDI-Konferenz als Webinar statt. Dabei standen der Informationsaustausch über alle sich in der Planung befindenden Konsortien und deren Vernetzung untereinander, im Zentrum. Des Weiteren hat die Deutsche Forschungsgemeinschaft (DFG) zur NFDI informiert und das neu gegründete Direktorat der NFDI hat sich vorgestellt.
Mehr erfahren
Wenn Sie mehr zum Thema NFDI erfahren möchten, schauen Sie auf nfdi.de vorbei oder wenden Sie sich einfach an das ServiceDesk. Das FDM-Team freut sich auf Ihre Nachricht.
Besuchen Sie auch die Seiten zur NFDI auf rwth-aachen.de.
—-
Inhaltlich verantwortlich für den Beitrag: Sophia Nosthoff und Jana Baur
Nachbericht zum offenen FDM-Netzwerktreffen am 10. Juni
Am 10.06.2020 fand das vierte offene Forschungsdatenmanagement (FDM)- Netzwerktreffen zum Thema Nationale Forschungsinfrastruktur (NFDI) statt. Auch diesmal trafen sich die Beteiligten aufgrund der aktuellen Situation online.
Vortrag I – Konzept der NFDI
Zum Einstieg wurde ein Vortrag, in dem sowohl die NFDI als auch die NFDI-Konsortien näher erklärt wurden, gehalten. Im Anschluss machte man sich die Vorteile des digitalen Zusammentreffens zu Eigen und nutzte die praktische Umfragen-Funktion von Zoom.
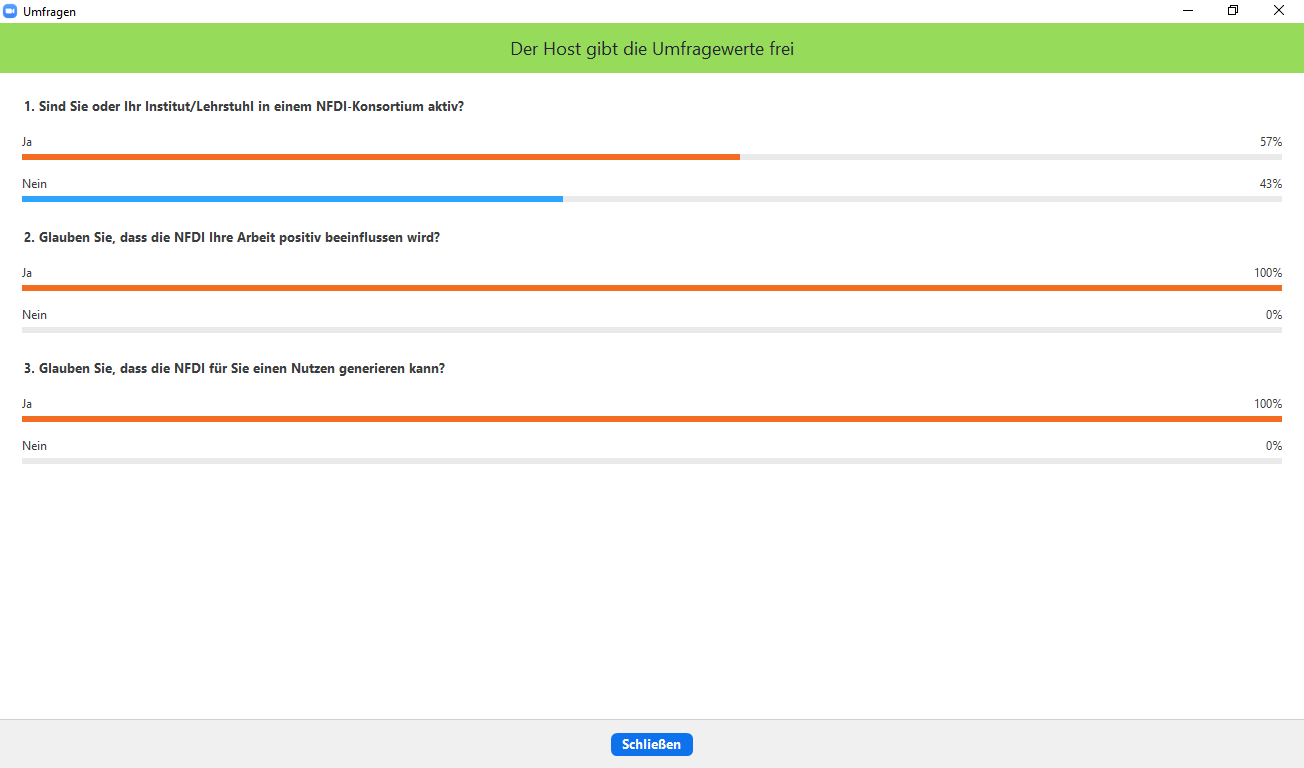
Dabei kam heraus, dass 57% der Teilnehmenden selbst oder zumindest das Institut bzw. der Lehrstuhl, dem sie angehören in einem NFDI-Konsortium aktiv sind. 43% der Anwesenden gaben dagegen an, in keinem NFDI-Konsortium aktiv zu sein. Trotzdem waren sich alle Beteiligten sicher, dass die NFDI ihre Arbeit positiv beeinflussen werde und für sie einen Nutzen generieren kann.
Vortrag II – Nationale Forschungsdateninfrastruktur für Ingenieurwesen
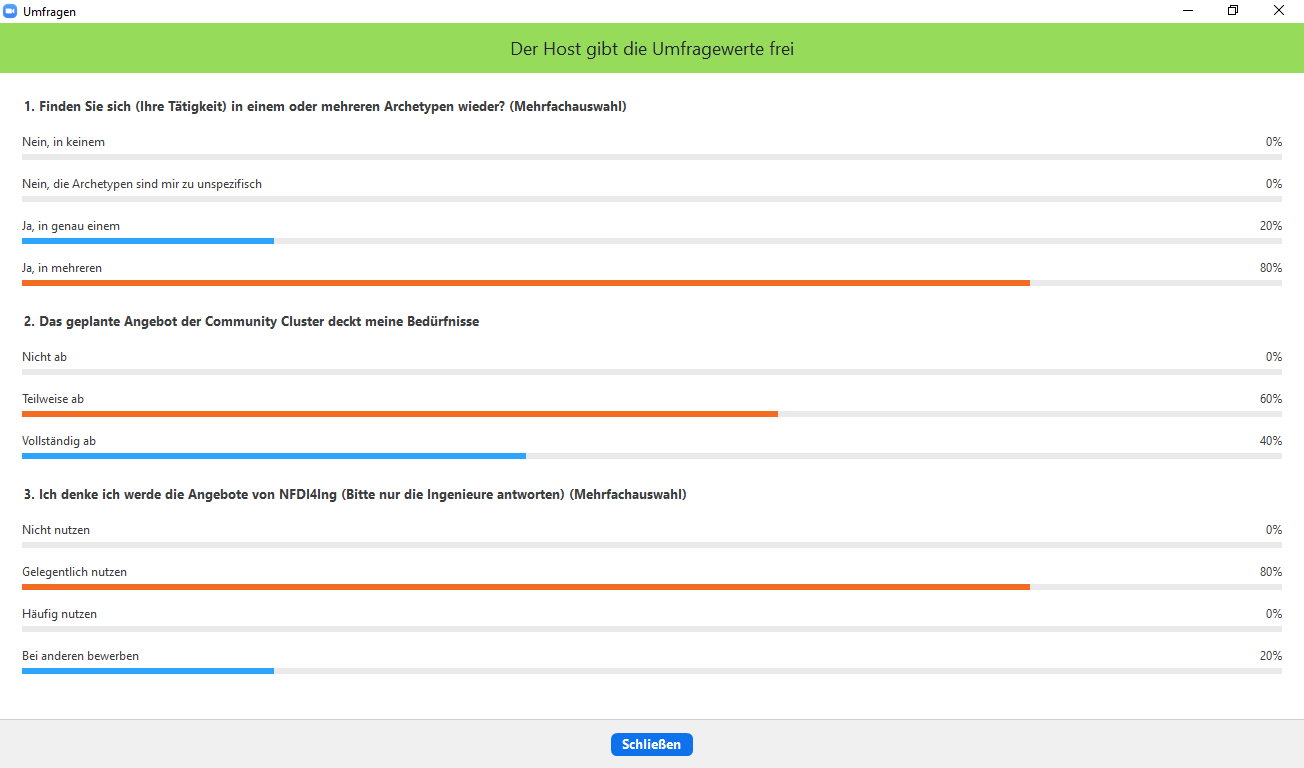
Nach der Vorstellung der NFDI wurde das Netzwerktreffen durch eine Präsentation zum Konsortium Nationale Forschungsdateninfrastruktur für Ingenieurwesen (NFDI4Ing) abgerundet. Neben den Herausforderungen des Konsortiums wurden auch das Archetypenkonzept von NFDI4Ing sowie die Base Services und Community Cluster erläutert. Nach dem Vortrag wurde eine weitere Umfrage durchgeführt. Die Ergebnisse zeigen, dass sowohl die Archetypen als auch die Community Cluster und die Angebote von NDFI4Ing auf positive Resonanz stoßen.
Diskussion im Plenum
Im Anschluss an die Vorträge gingen die Beteiligten in eine offene Diskussion über. Dabei wurden Fragen zu den Archetypen geklärt und sich darüber ausgetauscht wie man Forschende zum FDM motivieren könne.
Am Ende der Veranstaltungen legten die Anwesenden das Thema für das kommende Treffen fest. So soll es beim nächsten Mal um Daten zur Publikation gehen. Dabei wird das Vorgehen im SFB 985 – Mikrogele als Praxisbeispiel dienen.
Das nächste Netzwerktreffen – Save the Date
Datum: 08.07.2020
Uhrzeit: 10-12 Uhr
Ort: Zoom – Zugangsdaten auf Anfrage
Thema: Daten zur Publikation
Schreiben Sie uns
Bei Fragen zum FDM-Netzwerktreffen schreiben Sie einfach eine Nachricht an die offene Datasteward-Mailingliste, bei allgemeinen Fragen zum FDM an das ServiceDesk. Das FDM-Team freut sich auf Ihre Nachricht.
——-
Inhaltlich verantwortlich für den Beitrag: Sophia Nosthoff, Daniela Hausen und Jana Baur
NFDI–Förderung der Konsortien NFDI4Ing, NFDI4Chem und NFDI4Cat
 Bereits im Mai 2020 teilte die Deutsche Forschungsgemeinschaft (DFG) den teilnehmenden Initiativen der ersten Ausschreibungsrunde individuell mit, ob sie eine Förderung im Rahmen des Aufbaus einer Nationalen Forschungsdateninfrastruktur (NFDI) empfiehlt. Nun steht die endgültige Entscheidung über eine Förderung durch die Gemeinsame Wissenschaftskonferenz (GWK) fest:
Bereits im Mai 2020 teilte die Deutsche Forschungsgemeinschaft (DFG) den teilnehmenden Initiativen der ersten Ausschreibungsrunde individuell mit, ob sie eine Förderung im Rahmen des Aufbaus einer Nationalen Forschungsdateninfrastruktur (NFDI) empfiehlt. Nun steht die endgültige Entscheidung über eine Förderung durch die Gemeinsame Wissenschaftskonferenz (GWK) fest:
- NFDI4Culture – Konsortium für Forschungsdaten zu materiellen und immateriellen Kulturgütern (Geisteswissenschaften),
- KonsortSWD – Konsortium für die Sozial-, Bildungs-, Verhaltens- und Wirtschaftswissenschaften (Sozialwissenschaften),
- GHGA – Deutsches Humangenom-Phenomarchiv (Medizin),
- NFDI4Health – Nationale Forschungsdateninfrastruktur für personenbezogene Gesundheitsdaten (Medizin),
- DataPLANT – Daten in Pflanzen-Grundlagenforschung (Biologie), •
- NFDI4BioDiversität – Biodiversität, Ökologie und Umweltdaten (Biologie),
- NFDI4Cat – NFDI für Wissenschaften mit Bezug zur Katalyse (Chemie),
- NFDI4Chem – Fachkonsortium Chemie in der NFDI (Chemie),
- NFDI4Ing – Nationale Forschungsdateninfrastruktur für die Ingenieurwissenschaften (Ingenieurwissenschaften)
Die RWTH wird somit als Hauptantragsteller in dem Konsortium NFDI4Ing sowie als Mitantragsteller in den Konsortien NDFI4Cat und NFDI4Chem gefördert!
Nachbericht des Offenen Netzwerktreffens am 13. Mai
Am 13.05. fand das dritte offene Forschungsdatenmanagement (FDM)- Netzwerktreffen zum Thema: „Open Access, Open Data“ statt. Aufgrund der aktuellen Situation kamen die FDM-Verantwortlichen der operativen Ebene und Data Stewards diesmal online zusammen.
NFDI – Start der zweiten Ausschreibungsrunde
![]() Vergangene Woche hat die Deutsche Forschungsgemeinschaft (DFG) den teilnehmenden Initiativen der ersten Ausschreibungsrunde individuell mitgeteilt, ob sie eine Förderung im Rahmen des Aufbaus einer Nationalen Forschungsdateninfrastruktur (NFDI) empfiehlt. Die endgültige Entscheidung über eine mögliche Förderung trifft die Gemeinsame Wissenschaftskonferenz (GWK) am 26. Juni.
Vergangene Woche hat die Deutsche Forschungsgemeinschaft (DFG) den teilnehmenden Initiativen der ersten Ausschreibungsrunde individuell mitgeteilt, ob sie eine Förderung im Rahmen des Aufbaus einer Nationalen Forschungsdateninfrastruktur (NFDI) empfiehlt. Die endgültige Entscheidung über eine mögliche Förderung trifft die Gemeinsame Wissenschaftskonferenz (GWK) am 26. Juni.
Zu Beginn der Woche ist bereits die zweite Ausschreibungsrunde gestartet.
Umfrage im Rahmen von NFDI4Phys
Die Physikalisch-Technische Bundesanstalt (PTB), die Technische Informationsbibliothek (TIB) und die Deutsche Physikalische Gesellschaft (DPG) planen dieses Jahr das Konsortium „NFDI4Phys“ zu gründen.
Um die Anforderungen an eine künftige NFDI aus Sicht der Physik zu ermitteln, wurde eine Umfrage veröffentlicht, die sich an forschende Physikerinnen und Physiker richtet. Besonders interessant ist dabei die Meinung derer, deren Fachgebiet oder deren Bedürfnisse bisher nicht in einem Konsortium abgebildet sind. Die Umfrage läuft noch bis zum 10. April 2020.
Weiterlesen »Nationale Forschungsdateninfrastruktur: NFDI-Direktor im Amt
Der Aufbau der Nationalen Forschungsdateninfrastruktur (NFDI) schreitet voran. Am 29. Februar 2020 wurde Prof. York Sure-Vetter von den Vorsitzenden der Gemeinsamen Wissenschaftskonferenz (GWK) als Direktor der NFDI eingesetzt.
Vorgeschlagen wurde er der GWK von einer wissenschaftlich und wissenschaftsorganisatorisch ausgewiesenen Findungskommission. Für seine zukünftige Leitungstätigkeit bringe er ausgezeichnete fachliche und persönliche Voraussetzungen mit, heißt es in einer Pressemitteilung der GWK.
Weiterlesen »NFDI – RWTH ist einzige antragstellende Universität aus NRW
Vergangenen Oktober sind bei der Deutschen Forschungsgemeinschaft (DFG) 22 Anträge zur Förderung von Konsortien im Rahmen des Aufbaus einer Nationalen Forschungsdateninfrastruktur (NFDI) eingegangen.
Im Nachgang hat die DFG eine statistische Übersicht zum Antragseingang veröffentlicht. Während Baden-Württemberg im Ländervergleich vorne liegt, ist die RWTH Aachen University (RWTH) die einzige antragstellende Universität aus Nordrhein-Westfalen.
Weiterlesen »Reihe NFDI-Konsortien: NFDI4MobilTech, NFDI4MSE, PAHN-PaN und Text+
Im Rahmen der Reihe NFDI-Konsortien haben wir Ihnen beim letzten Mal die Initiativen NFDI4Health, NFDI4Ing und NFDI4Medicine vorgestellt. Heute geht es bereits in die letzte Runde dieser Reihe.
Last, but not least: die Initiativen NFDI4MobilTech, NFDI4MSE, PAHN-PaN und Text+. Viel Spaß beim Lesen.
Sprache:
Folgen Sie uns




