

Prozessorientierte Performance Engineering Service-Infrastruktur für wissenschaftliche Software an deutschen HPC-Zentren –kurz ProPE
Das DFG-geförderte Projekt „Prozessorientierte Performance Engineering Service-Infrastruktur für wissenschaftliche Software an deutschen HPC-Zentren“ –kurz ProPE.
Quelle: ProPE
Bei ProPE handelt es sich um ein Kooperationsprojekt der Rechenzentren der Friedrich-Alexander-Universität Erlangen (FAU), der TU Dresden (TUD) sowie der RWTH Aachen University (RWTH). Gestartet ist das Projekt 2017, gefördert von der Deutschen Forschungsgesellschaft, mit dem Ziel eine nachhaltige Blaupause für eine strukturierte, prozessorientierte Service-Infrastruktur für das Performance Engineering (PE) zu entwickeln. Dabei wurden gemeinsam Prozesse, Methoden und Werkzeuge evaluiert, entwickelt und implementiert, um die bundesweite PE-Infrastruktur zu schaffen, in der die HPC-Expertise der Zentren effizient zu nutzen.
Anwendung findet das Performance Engineering im Hochleistungsrechnen. Es ermöglicht Anwendungswissenschaftlerinnen und -wissenschaftlern Code mit nachweislich optimaler Hardware-Ressourcenauslastung auf Hochleistungssystemen zu entwickeln und zu nutzen. Damit gelingt es nicht nur eine zielorientierte und nachhaltige Anwenderunterstützung anzubieten, sondern auch als übergreifendes Angebot mehrerer Tier-2/3 HPC-Zentren die verteilten Kompetenzen optimal zu nutzen.
Strukturiert wurde das Projekt in fünf Arbeitspakete mit unterschiedlichen Aufgabenschwerpunkten zur Erreichung der Ziele. Alle Details sowie Empfehlungen aus diesem Projekt findet ihr im gemeinsam verfassten Whitepaper, das auf dem Blog des FAU-RRZE zum Download bereitsteht.
Die Arbeitspakete
Arbeitspaket 1: Performance Engineering
Performance Engineering (PE) ist ein wohldefinierter und strukturierter Prozess, um die Ressourceneffizienz von Anwendungsprogrammen zu verbessern. Das ProPE-Projekt bietet einen auf wissenschaftlichen Prinzipien basierenden PE-Prozess, der in Support und Schulungsaktivitäten eingesetzt werden kann. Durchführbar ist dieser Prozess in verschiedenen Detailgraden. Maßgebliche Ergebnisse des Arbeitspaketes Performance Engineering ist die Erweiterung der Performance Muster sowie die Etablierung eines Performance Logbuches, das in Markdown verfügbar bist. Es beinhaltet die Dokumentation von Aktivitäten und Ergebnissen in Hinblick auf das PE in strukturierter Form. Der Fokus dabei liegt auf einem möglichst standardisierten Datenaustausch hinsichtlich Formaten sowie einheitlicher Benennung von Metriken.
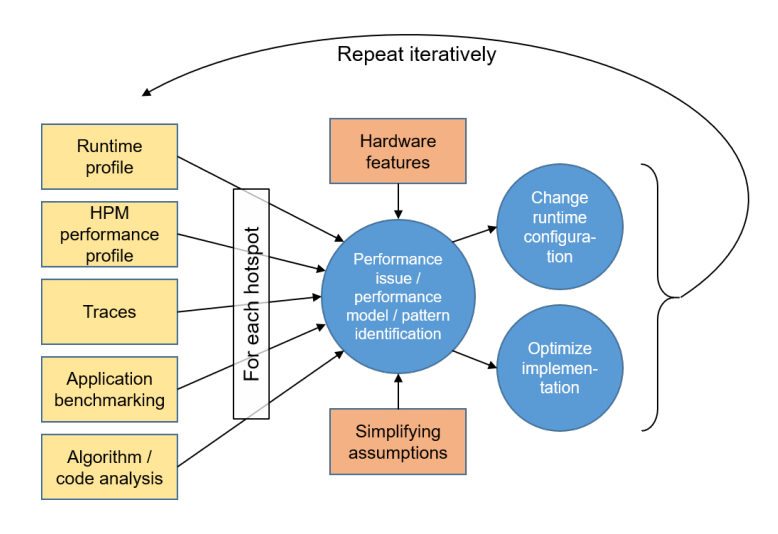
Die Abbildung zeigt eine vereinfachte Übersicht des PE-Prozesses. Die Konstruktion eines vollständigen Leistungsmodells oder die Identifizierung eines Musters für jeden spezifischen Hotspot sind optional und auch nicht immer möglich. Für jeden spezifischen Hotspot endet der Zyklus, sobald keine relevante Performance Verbesserung mehr erreicht werden kann. Das Hardware Performance Monitoring (HPM) erfolgt mit Hilfe von Hardware Performance Countern.
Quelle: ProPE
Arbeitspaket 2: Prozessmanagement
Ziel dieses Arbeitspaketes war es eine gemeinsame, flächendeckende, nachhaltige Support-Infrastruktur aufzubauen, um Nutzenden die notwendige Unterstützung anzubieten, die über die Grenzen des Heimatrechenzentrums hinausgeht. Mit Rückgriff auf die Expertise an den Kooperationszentren ist es somit möglich, Supportfälle zu lösen, die sonst ungelöst blieben. Ein gemeinsames Tickettool ermöglicht die Bearbeitung von standortübergreifenden PE-Supportanfragen. Dabei unterstützen Faktoren wie definierte Verantwortlichkeiten, Reaktions- und Eskalationszeiten sowie Ergebnissicherung durch Dokumentation den Kernprozess „ProPE-Support“. Mit freundlicher Unterstützung unserer „Friendly User“ konnte der Prozess in mehreren Testphasen genauer unter die Lupe genommen werden und bis zum Projektende optimiert werden.
Einen weiteren Teil im Prozessmanagement stellt die Entwicklung eines Kostenmodells dar, um den Nutzen von Performance Engineering auf HPC-Projekte über die Dauer der Projektlaufzeit zu ermitteln. Wesentliche Bestandteile, die dabei erhoben werden müssen sind neben Hardware und Brainware auch Energiekosten. Als Basis konnten in diesem Projekt die Durchschnittswerte der beteiligten Projektpartner beispielsweise hinsichtlich der Hardware-Kosten herangezogen werden.
Arbeitspaket 3: Performance Monitoring
Im Monitoring beschäftigt man sich grundsätzlich mit der Überwachung bestimmter Vorgänge. Auch im Kontext PE erfolgte eine intensive Auseinandersetzung mit dem Monitoring. Während des Projektes wurde ein Software-Stack entwickelt, das dem systemweiten Monitoring auf Hochleistungsrechnern dient. Ziel dessen ist es, ineffiziente Jobs zu identifizieren. Dabei werden sowohl Performance-Daten gesammelt und gespeichert, als auch analysiert und visualisiert. Für das Monitoring an der RWTH wurde das Speichern der Daten über Time Series Database (TSDB) InfluxDB realisiert. Der Überwachung dient auf den jeweiligen Knoten der Monitoring-Daemon Telegraf, der entsprechend erweitert wurde, um HPC-relevante Metriken zu verfassen.
Zusätzlich wurde in ProPE ein Web-Frontend entwickelt, das insgesamt den Überwachungs-Stack Pika beschreibt. Die FAU stellte dabei das Performance-Tool Likwid bereit, um an allen drei Zentren Daten zu erfassen. Ergänzend dazu wurde auch das ClusterCockpit entwickelt –eine Webanwendung für das Performance-Monitoring, um Nutzenden Zugang zu jobspezifischen Daten zu ermöglichen.
Arbeitspaket 4: Training
Der Schwerpunkt dieses Teilprojekts umfasste die Aus- und Weiterbildungsaktivitäten sowie die Entwicklung eines verteilten HPC-Curriculums. Um das HPC-Curriculum zu strukturieren, wurden verschiedene HPC-Zielgruppen definiert. Nach Durchsicht der in Deutschland und an den Tier-1/2 und -3 HPC-Zentren angebotenen HPC-Kursen wurden diese kategorisiert und mit verschiedenen Attributen versehen, einschließlich, aber nicht beschränkt auf erforderliche beziehungsweise erreichte Fähigkeiten sowie Niveaus der Fähigkeiten, gestaffelt in Anfänger, leicht Fortgeschrittene und Fortgeschrittene sowie Ort der Kurse und mehr.
Zusätzlich wurden die Kurse nach dem HPC Skill Tree kategorisiert, der jetzt Teil des HPC Certification Forums ist. Diese allgemeine Struktur der HPC-Kurse ermöglichte eine übersichtliche Darstellung der Schulungsaktivitäten in Deutschland und diente als Grundlage für das HPC-Curriculum. Darüber hinaus ermöglicht die HPC-Kursübersicht, die HPC-Ausbildungsbemühungen dorthin zu lenken, wo sie fehlen, insbesondere für verschiedene Einstiegszielgruppen und über das akademische Umfeld hinaus. Die Bewerbung der HPC-Kurse erfolgte auf mehreren internationalen Konferenzen und Workshops sowie über den Gauß-Allianz HPC-Kalender – die national etablierte HPC-Plattform. Während des gesamten Projekts wurde eine Reihe von HPC-Schulungsaktivitäten entwickelt und durchgeführt, die sich an verschiedene HPC-Zielgruppen richteten.
Arbeitspaket 5: HPC Wiki und Dokumentation
Der Aufbau einer Anwenderdokumentation allein ist bereits von hohem Wert für Nutzende, doch eine zentrale Dokumentation, die international erreichbar und an die heterogenen Zielgruppen adressiert ist, ist etwas ganz Besonderes. Mit dem HPC-Wiki ist es gelungen eine zentrale HPC-Dokumentation zu erschaffen, die sich insbesondere durch Nutzerfreundlichkeit, aber auch durch die einzigartige Art und Weise der Informationsaufbereitung herausstellt.

Quelle: HPC-Wiki
Hier finden sowohl Anfänger und Anfängerinnen als auch Expertinnen und Experten nicht nur generelle HPC-Informationen und Anleitungen, sondern auch ortsspezifische Informationen, die das jeweilige Rechenzentrum betreffen. Die Dokumentation basiert auf einem Media-Wiki mit einfachem Zugang und Wartung. Doppelpflege der Dokumentation kann vermieden werden und über die bequeme Authentifizierung per Shibboleth können neue Erkenntnisse und Anpassungen im HPC-Wiki eingepflegt werden. Dabei werden Einträge patrouilliert editiert und eine gemeinsame HPC-Dokumentation für und mit der Community erstellt. Details zum HPC-Wiki gibt es in diesem Beitrag.
ProPE in weiteren Projekten
Ergebnisse und Erkenntnisse des ProPE-Projektes finden auch nach Abschluss im Juni 2020 ihre Anwendung. So haben einige Ergebnisse Eingang in das DH.NRW-Projekt HPC.NRW gefunden. Mit HPC.NRW wird ein Kompetenznetzwerk innerhalb NRWs geschaffen, das nicht nur personell und organisatorisch den Verbund von großen Hochleistungsrechenzentren schafft, sondern auch durch Beratungsdienstleistungen von Tier-3-Zentren ergänzt wird. Konkret werden in diesem Projekt die Support-Struktur sowie die Service-Instanz auf dem Tickettool, das von der Gauß Allianz gehostet wird, für operative Anfragen genutzt. Auch das HPC-Wiki wird fortgeführt und bietet nun zusätzlich verschiedene Tutorial-Beiträge.
Aber auch über die Landesgrenzen NRWs hinaus finden viele Erfahrungswerte und Ergebnisse aus ProPE Eingang im Nationalen Hochleistungsrechnen (NHR). Neben den Ergebnissen zum Monitoring können auch Inhalte aus „Training“ und „Prozessmanagement“ einen Beitrag leisten und neue Projekte von den Entwicklungen aus dem Projekt ProPE profitieren.
Wir danken an dieser Stelle allen für die Zusammenarbeit und die tolle Unterstützung.
Verantwortlich für die Inhalte dieses Beitrags sind das ProPE-Projekt-Team, Nicole Filla und Linda Jörres.



