

Veranstaltungshinweis: Forschungsdatenmanagement mit GitLab – Berichte aus der Praxis
Am Mittwoch, den 02.09.2020, 14:00 – 15:30 Uhr findet die virtuelle Veranstaltung „Forschungsdatenmanagement mit GitLab – Berichte aus der Praxis“ statt.
Diese richtet an Forschungsdatenmanager*innen, Mitarbeiter*innen von Rechenzentren und interessierte Forscher*innen.
Gitlab
Die Open Source Webanwendung GitLab, die zum Management von Softwareprojekten auf Basis der Versionsverwaltung Git entwickelt wurde, eröffnet zahlreiche Einsatzmöglichkeiten im Forschungsdatenmanagement.
Es geht los: Reihe NFDI-Konsortien Vol. II
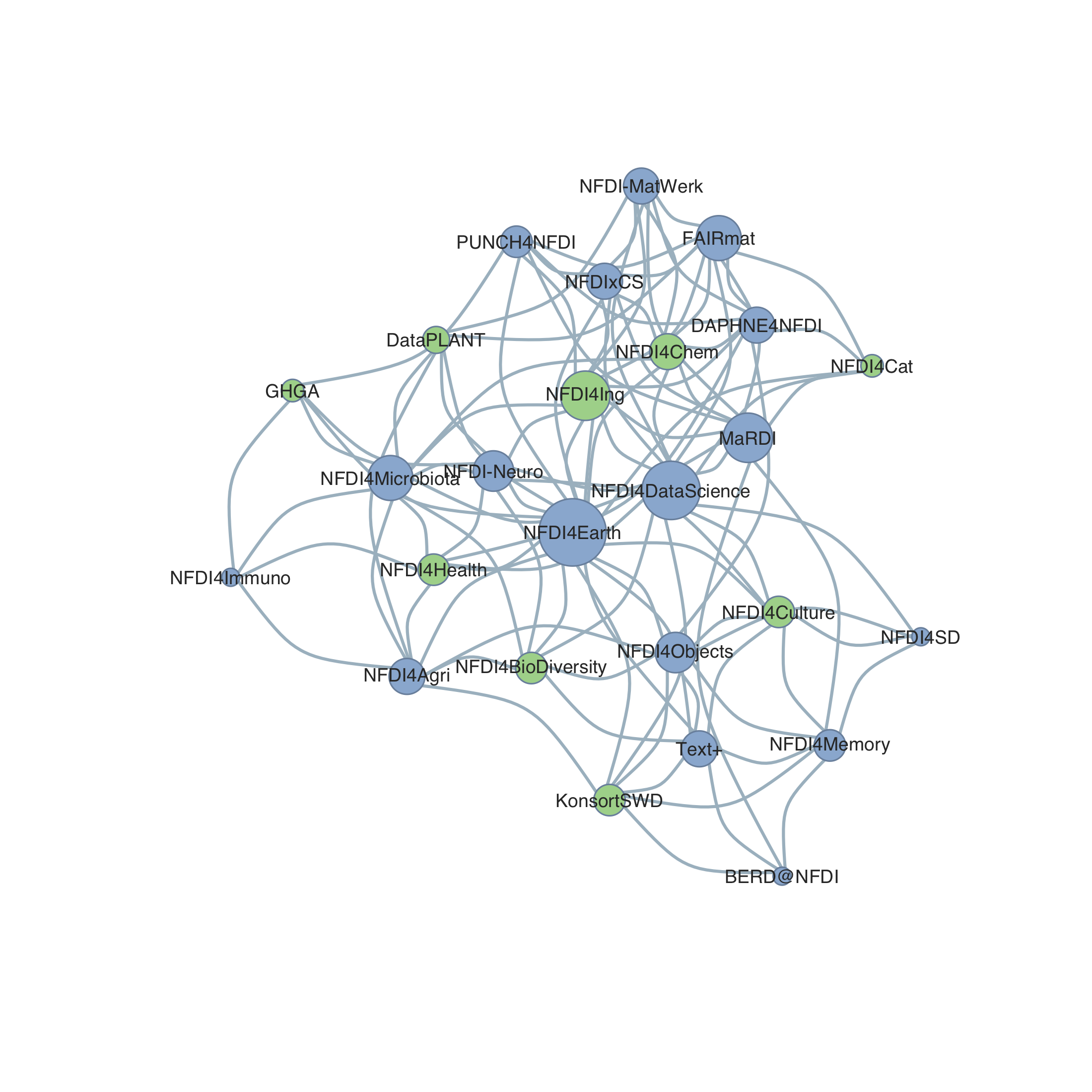
Dieses ungerichtete Netzwerk zeigt Verbindungen zu Konsortien, die die Antragstellung bereits erfolgreich durchlaufen haben (grün). (Quelle)
Erinnern Sie sich noch an unsere Reihe über die NFDI-Konsortien, die eine Absichtserklärung für eine Antragstellung im Jahr 2019 bei der Deutschen Forschungsgemeinschaft (DFG) eingereicht haben?
Nun gibt es eine zweite Auflage dieser Reihe!
Wie alles begann…
Im November 2018 haben Bund und Länder den Aufbau einer Nationalen Forschungsdateninfrastruktur (NFDI) beschlossen. Anfang Juni 2019 hat die Deutsche Forschungsgemeinschaft (DFG) mit einer Ausschreibung zur Antragstellung für die Förderung von Konsortien eingeladen.
Für die Antragsstellung waren gemeinsame Letters of Intent (LoI), also Absichtserklärungen, der Initiativen erforderlich, „um den zum kooperativen Aufbau der NFDI unerlässlichen Vernetzungsprozess zu unterstützen“ (Quelle). Die eingegangenen LoI wurden damals auf den Webseiten der DFG veröffentlicht und wir haben Ihnen im Anschluss die Konsortien und ihre Ziele vorgestellt.
Es geht weiter!
Inzwischen ist die erste Förderentscheidung gefallen und mit der Veröffentlichung der zweiten Ausschreibung zur Förderung von Konsortien ist bereits der Startschuss für die nächste Runde gefallen.
Bis zur Deadline am 15.08.2020 sind 18 verbindliche Voranmeldungen für eine Antragstellung im Jahr 2020 in Form von LoIs bei der DFG eingegangen, die diese nun veröffentlicht hat. Darunter befinden sich auch ein paar „alte Gesichter“, deren Anträge im letzten Jahr abgelehnt wurden und die ihr Glück in diesem Jahr erneut versuchen möchten.
Folgende Konsortien sind dabei:
- BERD@NFDI
- ColDiRPS
- DAPHNE4NFDI (ehemals DAPHNE)
- FAIRmat
- MaRDI
- NFDI4Agri
- NFDI4DataScience
- NFDI4Earth
- NFDI4Immuno
- NFDI4Memory
- NFDI4Microbiodata
- NFDI4Objects
- NFDI4SD
- NFDI-MatWerk (ehemals NFDI4MSE)
- NFDI-Neuro
- NFDIxCS
- PUNCH4NFDI
- Text+
Nun haben die Konsortien bis zum 30.09.2020 Zeit, um einen Antrag auf Förderung einzureichen.
Nachdem die erste Reihe über die NFDI-Konsortien beim letzten Mal auf so viel positive Resonanz gestoßen ist, möchten wir diese auch diesmal auf unserem Blog vorstellen.
Mehr erfahren
Wenn Sie mehr über die NFDI erfahren möchten, wenden Sie sich einfach an das ServiceDesk. Das FDM-Team freut sich auf Ihre Nachricht.
Besuchen Sie für weitere Informationen zum FDM auch die RWTH-Webseiten.
_____
Inhaltlich verantwortlich für den Beitrag: Sophia Nosthoff und Jana Baur
Online Diskussion NFDI: Neue Perspektiven in der kooperativen Wissenschaft!
 Die U Bremen Research Alliance veranstaltet eine moderierte Online-Diskussion zum Thema „Nationale Forschungsdateninfrastruktur (NFDI): „Neue Perspektiven in der kooperativen Wissenschaft!“.
Die U Bremen Research Alliance veranstaltet eine moderierte Online-Diskussion zum Thema „Nationale Forschungsdateninfrastruktur (NFDI): „Neue Perspektiven in der kooperativen Wissenschaft!“.
Wo besteht Diskussionsbedarf?
Es ist bekannt, dass mit dem Aufbau der NFDI die systematische Erschließung, nachhaltige Sicherung und die Zugänglichkeit von Datenbeständen der Wissenschaft und Forschung erzielt werden soll. Darüber hinaus sollen diese (inter-)national vernetzt werden.
Doch führen die Archivierung und die Bereitstellung der Daten im nationalen und internationalen Kontext wirklich zu einer kooperativeren Wissenschaft und einer Steigerung des Wissens?
NFDI Zenodo Community Collection ist online
Das NFDI-Direktorat hat bei Zenodo eine Community Collection eingerichtet, um Dokumente, Anträge und Präsentationen zur Nationalen Forschungsdateninfrastruktur zu teilen.
Zenodo
Zenodo ist eine Online-Speicherplattform, die sowohl für wissenschaftliche Datensätze, als auch für wissenschaftsbezogene Software, Publikationen, Berichte, Präsentationen usw. genutzt werden kann.
Der Speicherdienst Zenodo integriert den Repository-Dienst GitHub, um dort gespeicherte Quelltexte zitierfähig zu machen. Zenodo hilft somit Forschenden, Anerkennung zu erhalten, indem es die Forschungsergebnisse zitierfähig macht und sie durch OpenAIRE in bestehende Berichtslinien an Fördereinrichtungen wie die Europäische Kommission integriert. Zitierinformationen werden unter anderem auch an DataCite weitergeleitet.
NFDI – DFG veröffentlicht Statistiken zur Förderentscheidung der ersten Ausschreibungsrunde
Am 26. Juni 2020 wurde die Förderentscheidung der ersten Ausschreibungsrunde zur Förderung von Konsortien in der Nationalen Forschungsdateninfrastruktur (NFDI) durch die Gemeinsame Wissenschaftskonferenz (GWK) getroffen und die Förderung von neun NFDI-Konsortien beschlossen. Die Deutsche Forschungsgemeinschaft (DFG) hat im Nachgang eine statistische Übersicht zu der Förderentscheidung veröffentlicht.
Nachbericht zum offenen FDM-Netzwerktreffen am 08. Juli
Am 08.07.2020 fand das fünfte offene Forschungsdatenmanagement (FDM)- Netzwerktreffen zum Thema „Daten zur Publikation“ statt. Aufgrund der aktuell anhaltenden Situation kamen die FDM-Verantwortlichen der operativen Ebene und Data Stewards wieder online zusammen.
Vortrag – Daten zur Publikation
Der Einstieg erfolgte über einen Vortrag zum Thema der Sitzung. Es ging vor allem darum, warum und wie man Daten sichern sollte, auf denen eine Publikation beruht. Dafür wurden Beispiele für wissenschaftliches Fehlverhalten angeführt und erklärt, wie man Daten und Publikationen miteinander verlinkt. Weiterlesen »
Nachbericht der NFDI-Konferenz 2020
Am 8. Und 9. Juli 2020 fand die zweite NFDI-Konferenz als Online-Seminar statt.
Die Konferenz
Auf der diesjährigen NFDI-Konferenz ging es darum, die Vertreterinnen und Vertreter von geplanten Konsortien über das Konzept und die übergreifenden Ziele der NFDI sowie über die Eckpunkte der Antragstellung durch die DFG zu informieren.
Außerdem konnten sich die zur Förderung vorgeschlagenen und die geplanten Konsortien untereinander vorstellen und austauschen sowie den neuen NFDI-Direktor, Professor Dr. York Sure-Vetter, kennenlernen. Das Direktorat wird zukünftig die Selbstorganisation und Vernetzung der Konsortien zu konsortienübergreifenden Diensten, zu fachnahen oder datenähnlichen Angeboten und bei weiteren Fragen, unterstützen. (Quelle) Weiterlesen »
Nationale Forschungsdateninfrastruktur: Website NFDI.de online
Der Aufbau der Nationalen Forschungsdateninfrastruktur (NFDI) nimmt nach und nach immer mehr Gestalt an. Nachdem Ende Februar Prof. York Sure-Vetter von den Vorsitzenden der Gemeinsamen Wissenschaftskonferenz (GWK) als Direktor der NFDI eingesetzt wurde, ist im Mai die offizielle Homepage der NFDI online gegangen.
Immer auf dem neusten Stand
Die neue Website ist gut überschaubar und wird laufend aktualisiert.
Neben den aktuellen Entwicklungen und bevorstehenden Terminen findet man dort auch allgemeine Informationen über die Entstehung, Struktur und Aufbau der NFDI.
Das eingesetzte Direktorat der NFDI stellt sich unter der gleichnamigen Registerkarte vor.
Unter dem Reiter „Konsortien“ sind die antragstellenden Konsortien der ersten Förderungsrunde aufgelistet und die entsprechenden Websites für weitere Informationen verlinkt.
Die nächsten Schritte
Mit der Veröffentlichung der zweiten Ausschreibung zur Förderung von Konsortien am 25. Mai 2020 wurde der Startschuss für die nächste Runde gegeben. Die antragsstellenden Konsortien werden wir auch diesmal wieder im Rahmen einer Reihe auf diesem Blog vorstellen.
Momentan befindet sich die NFDI in der spannenden Phase. Am 26. Juni 2020 wurde die Förderentscheidung der GWK über die Anträge der ersten Runde verkündet.
Gestern und heute (08. & 09.07.20) fand außerdem die zweite NFDI-Konferenz als Webinar statt. Dabei standen der Informationsaustausch über alle sich in der Planung befindenden Konsortien und deren Vernetzung untereinander, im Zentrum. Des Weiteren hat die Deutsche Forschungsgemeinschaft (DFG) zur NFDI informiert und das neu gegründete Direktorat der NFDI hat sich vorgestellt.
Mehr erfahren
Wenn Sie mehr zum Thema NFDI erfahren möchten, schauen Sie auf nfdi.de vorbei oder wenden Sie sich einfach an das ServiceDesk. Das FDM-Team freut sich auf Ihre Nachricht.
Besuchen Sie auch die Seiten zur NFDI auf rwth-aachen.de.
—-
Inhaltlich verantwortlich für den Beitrag: Sophia Nosthoff und Jana Baur
Nachbericht zum offenen FDM-Netzwerktreffen am 10. Juni
Am 10.06.2020 fand das vierte offene Forschungsdatenmanagement (FDM)- Netzwerktreffen zum Thema Nationale Forschungsinfrastruktur (NFDI) statt. Auch diesmal trafen sich die Beteiligten aufgrund der aktuellen Situation online.
Vortrag I – Konzept der NFDI
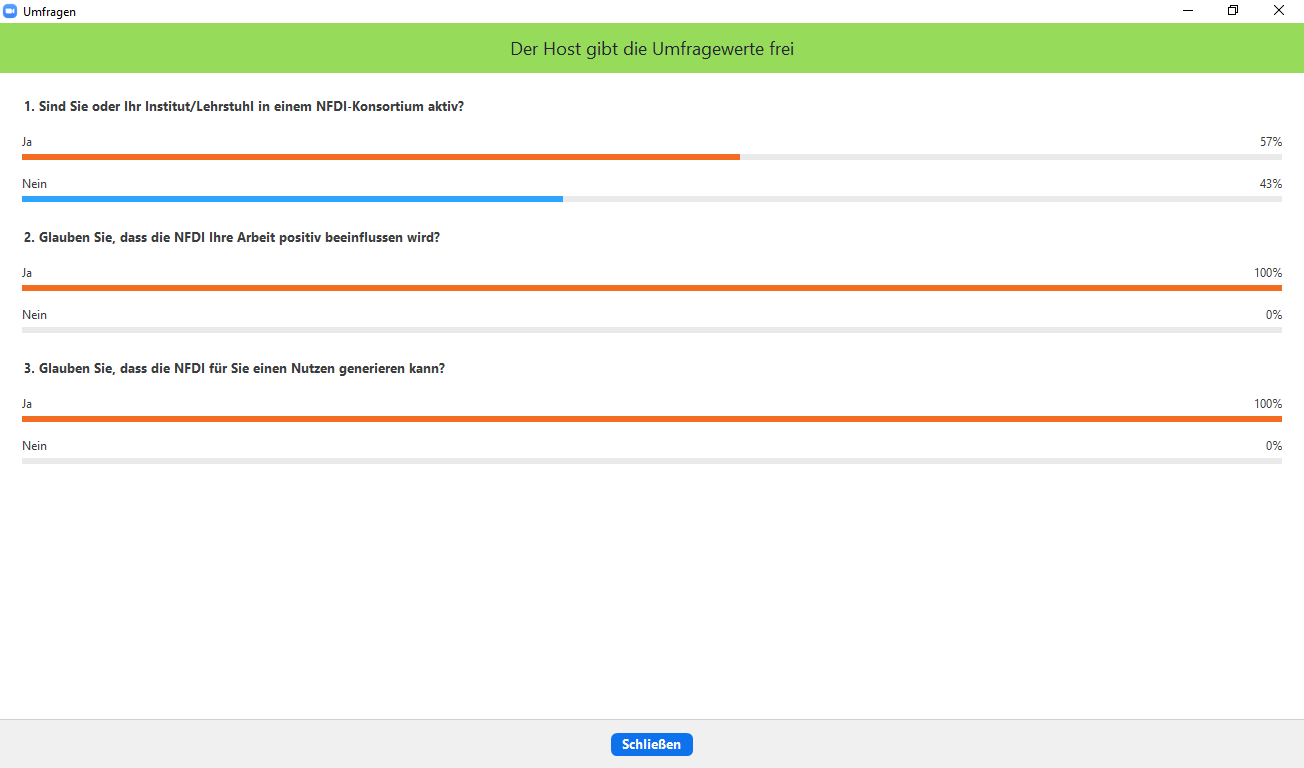
Zum Einstieg wurde ein Vortrag, in dem sowohl die NFDI als auch die NFDI-Konsortien näher erklärt wurden, gehalten. Im Anschluss machte man sich die Vorteile des digitalen Zusammentreffens zu Eigen und nutzte die praktische Umfragen-Funktion von Zoom.
Dabei kam heraus, dass 57% der Teilnehmenden selbst oder zumindest das Institut bzw. der Lehrstuhl, dem sie angehören in einem NFDI-Konsortium aktiv sind. 43% der Anwesenden gaben dagegen an, in keinem NFDI-Konsortium aktiv zu sein. Trotzdem waren sich alle Beteiligten sicher, dass die NFDI ihre Arbeit positiv beeinflussen werde und für sie einen Nutzen generieren kann.
Vortrag II – Nationale Forschungsdateninfrastruktur für Ingenieurwesen
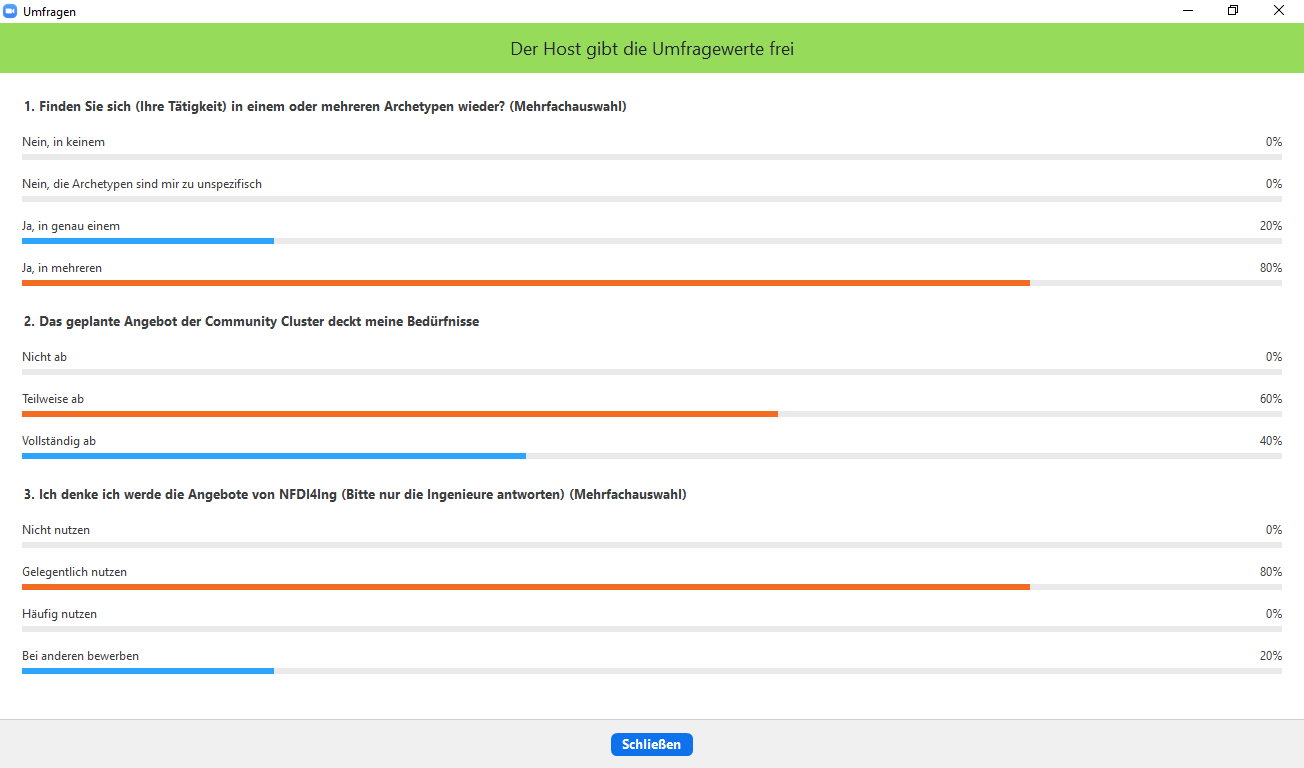
Nach der Vorstellung der NFDI wurde das Netzwerktreffen durch eine Präsentation zum Konsortium Nationale Forschungsdateninfrastruktur für Ingenieurwesen (NFDI4Ing) abgerundet. Neben den Herausforderungen des Konsortiums wurden auch das Archetypenkonzept von NFDI4Ing sowie die Base Services und Community Cluster erläutert. Nach dem Vortrag wurde eine weitere Umfrage durchgeführt. Die Ergebnisse zeigen, dass sowohl die Archetypen als auch die Community Cluster und die Angebote von NDFI4Ing auf positive Resonanz stoßen.
Diskussion im Plenum
Im Anschluss an die Vorträge gingen die Beteiligten in eine offene Diskussion über. Dabei wurden Fragen zu den Archetypen geklärt und sich darüber ausgetauscht wie man Forschende zum FDM motivieren könne.
Am Ende der Veranstaltungen legten die Anwesenden das Thema für das kommende Treffen fest. So soll es beim nächsten Mal um Daten zur Publikation gehen. Dabei wird das Vorgehen im SFB 985 – Mikrogele als Praxisbeispiel dienen.
Das nächste Netzwerktreffen – Save the Date
Datum: 08.07.2020
Uhrzeit: 10-12 Uhr
Ort: Zoom – Zugangsdaten auf Anfrage
Thema: Daten zur Publikation
Schreiben Sie uns
Bei Fragen zum FDM-Netzwerktreffen schreiben Sie einfach eine Nachricht an die offene Datasteward-Mailingliste, bei allgemeinen Fragen zum FDM an das ServiceDesk. Das FDM-Team freut sich auf Ihre Nachricht.
——-
Inhaltlich verantwortlich für den Beitrag: Sophia Nosthoff, Daniela Hausen und Jana Baur
Sprache:
Folgen Sie uns





{kind=link}