
Improving Student Success: Helping Study Planners by Evaluating Study Plans with Partial Orders
This post has been authored by Christian Rennert.
Improving Student Success: Helping Study Planners by Evaluating Study Plans with Partial Orders
In recent work, we’re tackling a critical challenge in higher education: how to help students complete their studies on time. For example, across all study programs offered in 2022 in Germany, nearly 247,000 students received their bachelor’s degree [1]. However, first-time graduates received their degree the same year on average after around 4 years of studies [2]. Understanding why these delays occur and what can be done to address them is vital for improving education systems.
Our recent research focuses on how study plans — blueprints for the sequence of courses that students must take — align with actual student behavior. Using data analysis techniques and partial order alignments from the field of conformance checking, we’ve developed a method to uncover where students deviate from their study plans and how / how much they deviate.
A New Approach that Supports to Understand Study Behavior
We use process models to represent a study plan and compare the resulting study plans to the actual traces students take, which are described by an educational event log. An educational event log contains the course enrollments and completions for each student. By modeling these traces as partial orders — an approach to avoid introducing a strict order when courses are taken in parallel during a semester — we can identify mismatches between the planned and actual course orders.

Figure 1: A proposed framework to obtain aggregated deviation information based on order-based and temporal-based deviations from the present study plan.
Our approach can be better explained using the framework shown in Figure 1. Here’s how it works:
1. Model the Study Plan and Translate the Event Log into Partial Orders:
You can model several study plans and check for the best fitting if there are changes to the study plans in between what may well happen in a university setting. The process model of the study plan describes for each course a range of terms that the exam can be taken in. It does not allow for any courses to be skipped since they are mandatory. Further, each student’s exam-taking behavior must be transformed into a partial order. Therefore, each exam try of a course is mapped to a relative term for the student and then a partial order is created. An actual study plan that we obtained data for is shown in Figure 2. In Figure 3, we show an example educational event log that one can create a partial order.

Figure 2: RWTH’s computer science study plan from 2018 being modeled as a process model.

Figure 3: Translation from an example educational event log to a partial order.
2. Computing the Partial Order Alignments:
To determine deviations in the ordering between the expected ordering in the study plan and the actual ordering of exams and courses for a student, a partial order alignment [3] is computed. Such an alignment is a sequence of synchronous moves between both the trace and the model, log moves, and model moves. Here, you choose the best fitting alignment in case you have several study plans that may be equally possible for a student.
3. Aggregate Information Based on the Alignment and Term Distances Between the Actual and Expected Terms for a Course:
Based on the partial order alignment, we know that each course occurs in the model side either as a model or as a synchronous move. Therefore, there are the following relative positions that a course can have that is happening on the log side:
-
-
- A course occurs synchronously between the process model and the partial order: This means that a student is likely to agree to their exam-taking order with the expected order.
- At an earlier position in the partial order alignment a log move occurs with the course ID and later the mandatory model move: The student is likely to have taken the course earlier than expected.
- At a later position in the partial order alignment a log move occurs with the course ID and earlier the mandatory model move: The student is likely to have taken the course later than expected.
- There is only a model move for a course and no log move: This may be some data quality issue, where a course is missing in the educational event log for the student.
-

Figure 4: Example of the different ordering-based cases for a total order (right) and a partial order (left) and their partial order alignments. Obtaining such different alignments is also the reason why we use partial orders instead of total orders which is beyond the scope of this blogpost.
This derived information from the partial order alignments is then combined with some course-taking distances between the actual and the expected term that the course should be taken in. The distance is calculated in years and for a cohort of students the combination of an order-based relation and the corresponding temporal distance for a course are combined and counted, resulting in the data shown in Table 1 and Table 2.

Table 1: An excerpt from the aggregated result for the investigated students and the 2010 study plan.

Table 2: An excerpt from the aggregated result for the investigated students and the 2018 study plan.
Key Insights from the Research
Using data from RWTH Aachen University, we applied this approach to study plans from 2010 and 2018. Here’s what we found:
- Shifting Courses between expected and actual position: We can detect whether courses are moved backward or forward in the order in which courses should be taken. For example, courses C05 and C12 in Table 1 are moved forward by a smaller fraction of students while most students comply between expected position and expected time. Courses C16 and C18 are courses that occur more often to be taken later in studies and may lead to a longer study duration since they are most often also delayed by at least one year.
- Well-conforming courses: We can check if courses conform well between expectations and actual data. For example, the course C17 in Table 2 is taken from most students in the right order and a lower fraction of students take a course late.
- Adaptations over study plan: While study plans can change over time, this can have an effect on the conformance between students and study plans. Here, we can compare courses C12 and C17 between the aggregated results in Table 1 and Table 2 that belong to the analysis of a 2010 and a 2018 computer science study plan, respectively. While the change improved conformance for course C17, changes to course C12 reduced conformance here.
Possible Things to Come
Our findings highlight the potential for universities to use this methodology to evaluate and refine their study plans systematically. The results derived may also be used to enhance the information within our event logs directly, e.g., by adding a notion for an unconforming activity using what type of non-conformance it is. However, since optimal alignments are not necessarily deterministic, there may be improvements to make towards the reproducibility of each run of the presented framework and its interpretability. Further, we could also analyze the framework’s capability for educational event logs of other degree programs, and we can imagine that the framework can also be used to gain deeper insights into a cohort of students or for other metrics as well. We can also imagine the approach to be applicable to other types of event data that contain relative timings and corresponding process models.
Further Reading
This post is based on the research paper [3] that was accepted for publication and was presented at the EduPM – ICPM 2024 Workshop. Please find the preprint in the references section.
References:
[1] The average study duration of first-degree university graduates in Germany from 2003 to 2023, https://www.statista.com/statistics/584454/bachelor-and-master-degrees-number-universities-germany/, 2024, last access 2025-01-21
[2] Number of Bachelor’s and Master’s degrees in universities in Germany from 2000 to 2023, https://www.statista.com/statistics/584454/bachelor-and-master-degrees-number-universities-germany/, 2023, last access 2025-01-21
[3] Rennert, Christian, Mahsa Pourbafrani, and Wil van der Aalst. “Evaluation of Study Plans using Partial Orders.” arXiv preprint arXiv:2410.03314 (2024).
Detecting and Explaining Process Variability Across Performance Dimensions
This post has been authored by Ali Norouzifar.
Detecting and Explaining Process Variability Across Performance Dimensions
In the dynamic landscape of business processes, understanding variability is pivotal for organizations aiming to optimize their workflows and respond to inefficiencies. While much of the focus in process mining has been on detecting changes over time [1], such as concept drift, there is a less-explored yet equally critical dimension to consider: variability across performance metrics like case durations, risk scores, and other indicators relevant to business goals.
In this blog post, we summarize the process variant identification framework presented in [2], outlining the advancements made and potential future directions. The research introduces a novel framework that detects change points across performance metrics using a sliding window technique combined with the earth mover’s distance to evaluate significant control-flow changes. While the framework excels at identifying where variability occurs, the task of explaining these detected control-flow changes across performance dimensions remains an open challenge. This ongoing work, currently under review, aims to bridge that gap. The framework not only pinpoints variability but also provides actionable insights into the reasons and mechanisms behind process changes, empowering organizations to make informed, data-driven decisions.
A Motivating Example
To demonstrate how our algorithm works, we use a simple yet illustrative motivating example. In this example, the exact change points are known, allowing us to clearly show how our technique identifies and explains these changes. We encourage you to explore the implemented tool yourself by visiting our GitHub repository (https://github.com/aliNorouzifar/X-PVI). Using Docker, you can pull the image and follow along with this blog post to test the algorithm in action.
Processes are inherently complex, influenced by various dimensions beyond just time. For instance, consider the BPMN model illustrating a synthetic claim-handling process in Figure 1. In this process, the risk score of a case significantly impacts execution behavior. High-risk cases (risk score between 10 and 100) might be terminated early through cancellation after creating an application, whereas low-risk cases (risk score between 0 and 3) may bypass additional checks, creating distinct behavioral patterns. These variations, often hidden when processes are analyzed from a singular perspective like time, can lead to overlooked opportunities for targeted improvements. The event log corresponding to this example consisting of 10000 cases is available online (https://github.com/aliNorouzifar/X-PVI/blob/master/assets/test.xes). We use this event log in the following sections to show the capabilities of our framework.
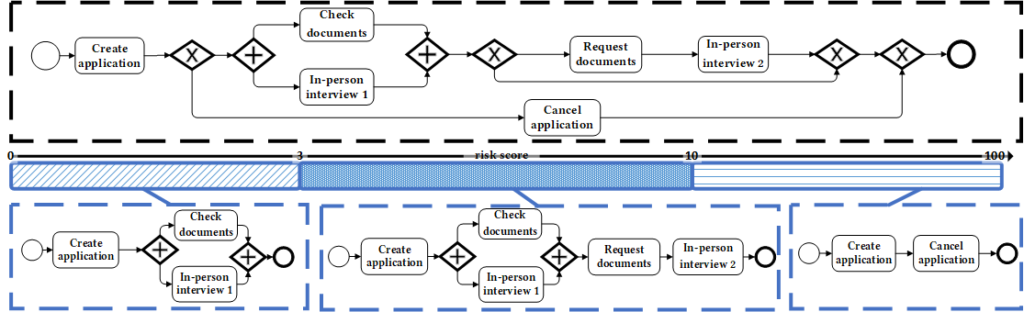
Figure 1: BPMN representation of a claim handling process, highlighting variations based on risk score [1].
The Explainable Process Variant Identification Framework
Our framework combines robust detection of control-flow changes with enhanced explainability, focusing of the performance dimensions. Here is how it works:
Change Point Detection with Earth Mover s Distance:
First, we sort all the cases based on the selected process indicator. Once the cases are sorted, the user specifies the desired number of buckets, ensuring that each bucket contains an equal frequency of cases. Next, we apply a sliding window approach, where the window spans w buckets on both the left and right sides. This sliding window moves across the range of the performance indicator, from the beginning to the end. At each step, we calculate the earth mover s distance to measure the difference between the distributions on the left and right sides of the window. Refer to [3] for a detailed explanation of the earth mover’s distance, its mathematical foundations, and its practical applications. The results are visualized in a heatmap, which highlights specific points where significant process changes occur. In Figure 2, we show a simple example considering 15 buckets and window size of 3.
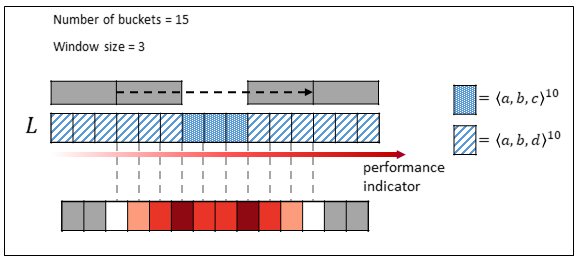
Figure 2: An example of change detection with earth mover s distance.
To determine the change points, we use a user-defined threshold that specifies the significance level for the earth mover s distance, enabling the segmentation process.
In our motivating example (cf. Figure 1), the risk score of the cases is selected as the performance indicator. Considering 100 buckets, each bucket contains 1% of the total cases. The first bucket includes the 1% of cases with the lowest risk scores, while the last bucket contains the 1% of cases with the highest risk scores. In Figure 3, visualizations for different window sizes (2, 5, 10, and 15) are provided. Using a window size of 2 and a significance threshold of 0.15, we can identify three distinct segments. These change points are utilized to define meaningful process segments that align with our initial understanding of the process dynamics. The identified change points are at risk score values of 3.0 and 10.0, accordingly the process is divided into three segments: (1) cases with risk scores between 0 and 3, (2) cases with risk scores between 3 and 10, and (3) cases with risk scores between 10 and 100.

Figure 3: Control flow change detection using the earth mover s distance framework with 100 buckets and different window sizes w∊{2, 5, 10, 15}. The color intensity indicates the magnitude of control-flow changes.
Explainability Extraction:
The explainability extraction framework begins with the feature space generation, where we derive all possible declarative constraints from the set of activities in the event log. This set can potentially be very large. For a detailed explanation of declarative constraints, refer to [4]. Below are some examples of declarative constraints derived from the motivating example event log:
* End(cancel application): cancel application is the last to occur.
* AtLeast1(check documents): check documents occurs at least once.
* Response(create application, cancel application): If create application occurs, then cancel application occurs after create application.
* CoExistence( in-person interview 1, check documents): If in-person interview 1 occurs, check documents occurs as well and vice versa.
For each sliding window, we calculate a specific evaluation metric for each declarative constraint, such as its confidence. For example, if the event create application occurs 100 times within a window, and only 10 of those instances are followed by cancel application, the confidence of the constraint Response(create application, cancel application) in that window is 10/100 or 10%. As the sliding window moves across the range of the process indicator, this evaluation metric is recalculated at each step. This process generates a behavioral signal for each constraint, providing insights into how the behavior evolves across different segments of the process. We do some preprocessing and only include the informative signals, for example, some of the features, may have constant value signals, we remove such signal.
The next step involves clustering the behavioral signals, grouping together signals that exhibit similar changes. This clustering serves as a visual aid, highlighting which signals change in tandem and how these clusters correspond to distinct segments identified during the earth mover s based change point detection step. By analyzing the correlation between the behavioral signals within these clusters and the identified segments, we gain valuable insights into the control-flow characteristics driving process variations as the range of the process indicator shifts from one segment to another.
Considering the window size of 2 and the significant distance threshold of 0.15, Figure 4 visualizes the different behavioral signals clustered into 7 groups. In Figure 5, the correlation between the clusters of behavioral signals and identified segments is illustrated.
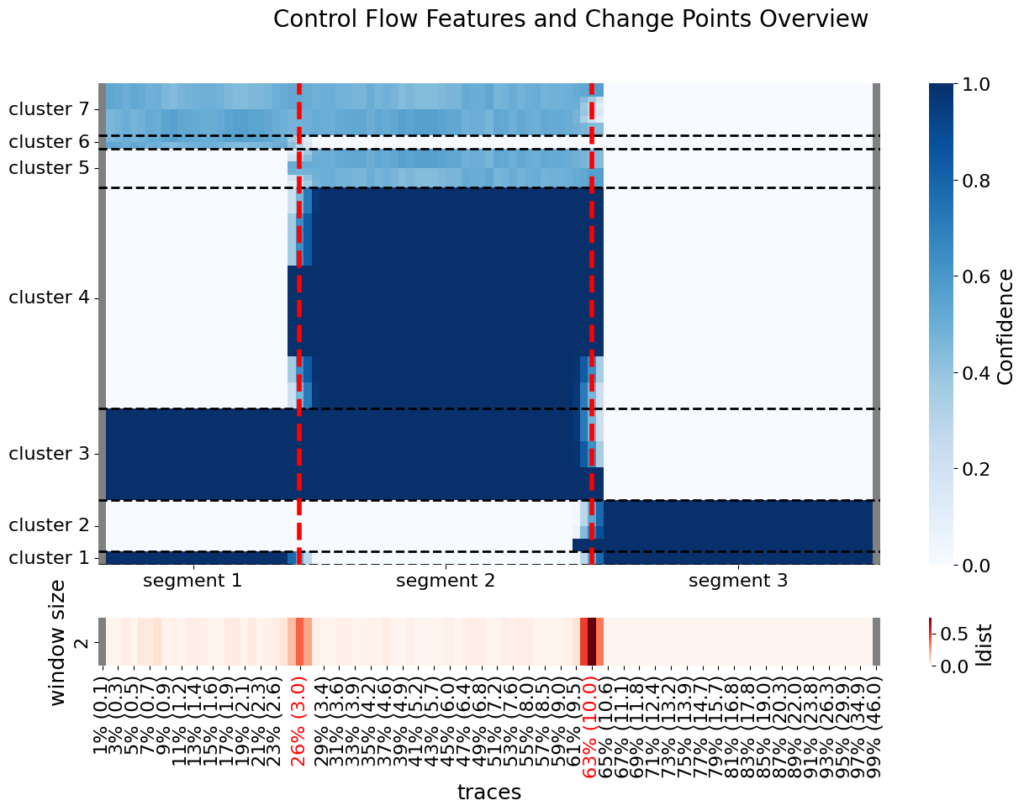
Figure 4: Control flow feature clusters derived from behavioral signals and change-point detection.
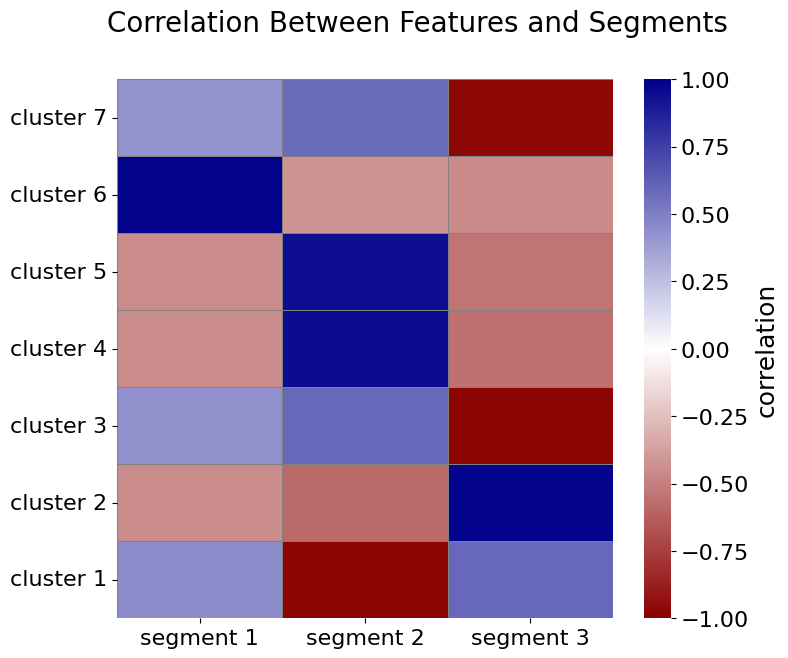
Figure 5: Correlation analysis between identified segments and behavioral feature clusters. The heatmap highlights positive and negative correlations, illustrating how specific clusters explain segment-level behaviors.
For instance, the strong negative correlation between Cluster 1 and Segment 2 indicates that the behavioral signals in this cluster have significantly higher values in other segments compared to Segment 2. To enhance readability, some examples of declarative constraints from Cluster 1, translated into natural language, are as follows:
* in-person appointment 2 must never occur.
* request documents must never occur.
The strong positive correlation between Cluster 2 and Segment 3 indicates that the behavioral signals in this cluster have significantly higher values in Segment 3 compared to other segments. Below are some examples of declarative constraints from Cluster 2:
* create application and cancel appointment occurs if and only if cancel appointment immediately follows create application.
* cancel appointment is the last to occur.
* check documents must never occur
* If create application occurs, then cancel appointment occurs immediately after it.
* in-person appointment 1 must never occur.
* cancel appointment occurs only if create application occurs immediately before it.
A comparison of the extracted explainability with the ground truth, as illustrated in Figure 1, demonstrates that the results align closely with the actual process dynamics. This indicates that the designed framework is both effective at identifying changes and capable of providing meaningful explanations for them.
Why This Matters
Traditional process mining methods often overlook the rich variability that exists across performance dimensions. Our framework addresses this gap by not only detecting process changes but also integrating explainability into the analysis. This empowers process experts to better understand the detected changes and take informed actions.
The result? A powerful tool for uncovering hidden inefficiencies, adapting workflows to dynamic requirements, and driving continuous improvement. Additionally, our open-source implementation ensures accessibility for organizations across industries, enabling widespread adoption and collaboration. Please check our GitHub repository for more information https://github.com/aliNorouzifar/X-PVI.
We are committed to continuous improvement, regularly updating the framework to enhance its functionality and usability. Your feedback and insights are invaluable to us. We welcome your suggestions and encourage you to report any issues or potential enhancements to further refine this approach. Here is my email address: ali.norouzifar@pads.rwth-aachen.de
References:
[1] Sato, D.M.V., De Freitas, S.C., Barddal, J.P. and Scalabrin, E.E., 2021. A survey on concept drift in process mining. ACM Computing Surveys (CSUR), 54(9), pp.1-38.
[2] Norouzifar, A., Rafiei, M., Dees, M. and van der Aalst, W., 2024, May. Process Variant Analysis Across Continuous Features: A Novel Framework. In International Conference on Business Process Modeling, Development and Support (pp. 129-142). Cham: Springer Nature Switzerland.
[3] Leemans, S.J., van der Aalst, W.M., Brockhoff, T. and Polyvyanyy, A., 2021. Stochastic process mining: Earth movers stochastic conformance. Information Systems, 102, p.101724.
[4] Di Ciccio, C. and Montali, M., 2022. Declarative Process Specifications: Reasoning, Discovery, Monitoring. Process mining handbook, 448, pp.108-152.
Introducing PM-LLM-Benchmark v2.0: Raising the Bar for Process-Mining-Specific Large Language Model Evaluation
This post has been authored by Alessandro Berti.
1. Introduction
In recent years, the synergy between process mining (PM) and large language models (LLMs) has grown at a remarkable pace. Process mining, which focuses on analyzing event logs to extract insights into real-world business processes, benefits significantly from the context understanding and domain knowledge provided by state-of-the-art LLMs. Despite these promising developments, until recently, there was no specific benchmark for evaluating LLM performance in process mining tasks.
To address this gap, we introduced PM-LLM-Benchmark v1.0 (see the paper)—the first attempt to systematically and qualitatively assess how effectively LLMs handle process mining questions. Now, we are excited to announce PM-LLM-Benchmark v2.0, a comprehensive update that features an expanded range of more challenging prompts and scenarios, along with the continued use of an expert LLM serving as a judge (i.e., LLM-as-a-Judge) to automate the grading process.
This post provides an overview of PM-LLM-Benchmark v2.0, highlighting its major features, improvements over v1.0, and the significance of LLM-as-a-Judge for robust evaluations.
2. PM-LLM-Benchmark v2.0 Highlights
2.1 A New and More Complex Prompt Set
PM-LLM-Benchmark v2.0 is a drop-in replacement for v1.0, designed to push the boundaries of what LLMs can handle in process mining. While the same categories of tasks have been preserved to allow continuity in evaluations, the prompts are more complex and detailed, spanning:
- Contextual understanding of event logs, including inference of case IDs, event context, and process structure.
- Conformance checking and the detection of anomalies in textual descriptions or logs.
- Generation and modification of declarative and procedural process models.
- Process querying and reading process models, both textual and visual (including diagrams).
- Hypothesis generation to test domain knowledge.
- Assessment of unfairness in processes and potential mitigations.
- Diagram reading and interpretation for advanced scenarios.
These new prompts ensure that high-performing models from v1.0 will face fresh challenges and demonstrate whether their reasoning capabilities continue to scale as tasks become more intricate.
2.2 LLM-as-a-Judge: Automated Expert Evaluation
A defining feature of PM-LLM-Benchmark is its use of an expert LLM to evaluate (grade) the responses of other LLMs. We refer to this approach as LLM-as-a-Judge. This setup enables:
1. Systematic Scoring: Each response is scored from 1.0 (minimum) to 10.0 (maximum) according to how well it addresses the question or prompt.
2. Reproducible Assessments: By relying on a consistent “judge” model, different LLMs can be fairly compared using the same grading logic.
3. Scalability: The automated evaluation pipeline makes it easy to add new models or updated versions, as their outputs can be quickly scored without the need for full manual review.
For example, textual answers are judged with a prompt of the form:
Given the following question: [QUESTION CONTENT], how would you grade the following answer from 1.0 (minimum) to 10.0 (maximum)? [MODEL ANSWER]
When an image-based question is supported, the judge LLM is asked to:
Given the attached image, how would you grade the following answer from 1.0 (minimum) to 10.0 (maximum)? [MODEL ANSWER]
The final score for a model on the benchmark is computed by summing all scores across the questions and dividing by 10.
2.3 Scripts and Usage
We have included answer.py and evalscript.py to facilitate the benchmark procedure:
1. answer.py: Executes the prompts against a chosen LLM (e.g., an OpenAI model), collecting outputs.
2. evalscript.py: Takes the collected outputs and feeds them to the LLM-as-a-Judge for automated grading.
Users can customize the API keys within answering_api_key.txt and judge_api_key.txt, and configure which model or API endpoint to query for both the answering and judging phases.
3. Benchmark Categories
PM-LLM-Benchmark v2.0 continues to organize tasks into several categories, each reflecting real-world challenges in process mining:
1. Category 1: Contextual understanding—tasks like inferring case IDs and restructuring events.
2. Category 2: Conformance checking—identifying anomalies in textual descriptions or event logs.
3. Category 3: Model generation and modification—creating and editing both declarative and procedural process models.
4. Category 4: Process querying—answering questions that require deeper introspection of the process models or logs.
5. Category 5: Hypothesis generation—proposing insightful research or improvement questions based on the provided data.
6. Category 6: Fairness considerations—detecting and mitigating unfairness in processes and resources.
7. Category 7: Diagram interpretation—examining an LLM’s ability to read, understand, and reason about process mining diagrams.
Each category tests different aspects of an LLM’s capacity, from linguistic comprehension to domain-specific reasoning.
4. Leaderboards and New Baselines
Following the approach of v1.0, PM-LLM-Benchmark v2.0 includes leaderboards to track the performance of various LLMs (see the leaderboard_gpt-4o-2024-11-20.md). Our latest results demonstrate that even the most capable current models achieve only around 7.5 out of 10, indicating the increased difficulty of v2.0 relative to v1.0, where performances had largely plateaued near the 9–10 range.
Model Highlights
- OpenAI O1 & O1 Pro Mode:
The new O1 model and the enhanced O1 Pro Mode deliver strong performance, with O1 Pro Mode showing about a 5% improvement over O1. Some initial concerns about the standard O1 model’s shorter reasoning depth have been largely mitigated by these results. - Google Gemini-2.0-flash-exp and gemini-exp-1206:
Gemini-2.0-flash-exp shows performance comparable to the established gemini-1.5-pro-002. However, the experimental gemini-exp-1206 variant, expected to inform Gemini 2.0 Pro, displays promising improvements over earlier Gemini releases. Overall, Gemini models fall slightly behind the O1 series on v2.0 tasks.
5. How to Get Started
1. Clone the Repository: Access the PM-LLM-Benchmark v2.0 repository, which contains the questions/ folder and scripts like answer.py and evalscript.py.
2. Install Dependencies: Make sure you have the necessary Python packages (e.g., requests, openai, etc.).
3. Configure API Keys: Place your API keys in answering_api_key.txt and judge_api_key.txt.
4. Run the Benchmark:
- Execute python answer.py to generate LLM responses to the v2.0 prompts.
- Run python evalscript.py to evaluate and obtain the final scores using an expert LLM.
5. Analyze the Results: Compare the results in the generated scoreboard to see where your chosen model excels and where it struggles.
6. Conclusion and Outlook
PM-LLM-Benchmark v2.0 raises the bar for process-mining-specific LLM evaluations, ensuring that continued improvements in model architectures and capabilities are tested against truly challenging and domain-specific tasks. Leveraging LLM-as-a-Judge also fosters a consistent, automated, and scalable evaluation paradigm.
Whether you are an LLM researcher exploring specialized domains like process mining, or a practitioner who wants to identify the best model for analyzing process logs and diagrams, we invite you to test your models on PM-LLM-Benchmark v2.0. The expanded prompts and systematic grading method provide a rigorous environment in which to measure and improve LLM performance.
References & Further Reading
- Original PM-LLM-Benchmark v1.0 Paper: https://arxiv.org/pdf/2407.13244
- Leaderboard (updated regularly): leaderboard_gpt-4o-2024-11-20.md
What are Local Process Models? (and Why do They Matter?)
This post has been authored by Viki Peeva.
Local process models (LPMs) are behavioral patterns that describe process fragments and are used to analyze processes.
If we take our “definition” apart, there are three important parts regarding LPMs:
- They are a specific type of pattern.
- They do not care about the entire process but only about parts of it.
- They help us analyze and understand the process locally.
Now, let us begin!
Why are patterns important?
In data science, patterns are recurring structures or trends in the dataset. Frequent item sets and building association rules are classic examples. However, we can also consider pattern mining when we find correlations (correlation patterns), classification or clustering boundaries (separation patterns), the common ground of outliers (outlier patterns), or the famous king – man + woman = queen in word embeddings (latent patterns).
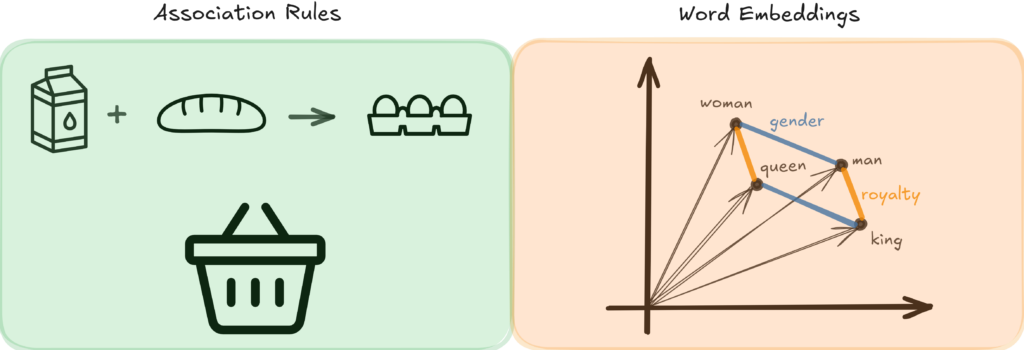
Example association rule and word embedding pattern.
Conclusion: Patterns are omnipresent in the data world, even when it does not look like that at first glance. This deduction also holds with event data. In the process mining world, we characterize patterns linked to control flow as behavioral patterns. So, next, we look at what are behavioral patterns.
What are behavioral patterns?
Consider sequential patterns, like the market basket analysis, but with time. Such sequential patterns are one example of behavioral patterns. Sequential patterns describe sequences of steps in our analyzing process [1]. If that process is buying in the supermarket, we can track what is put in the basket and in which order. That way, the supermarket might adapt product placement. However, considering hundreds or even thousands of customers visit the supermarket every day, if we try to model all their behaviors, it will probably look like a big plate of spaghetti. Hence, patterns.
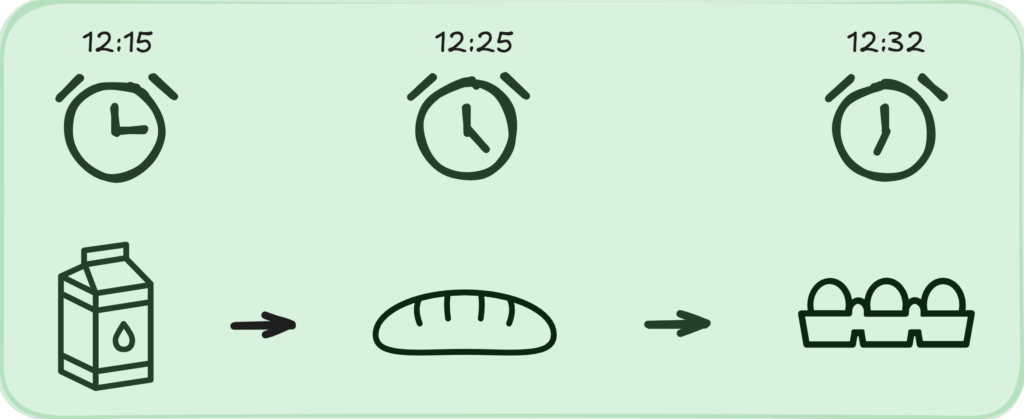
Example sequential patters for buying behavior in supermarket.
The term behavioral patterns also covers patterns allowing more elaborate control-flow constructs* or defining constraints. For example, while sequences can model only sequential relationships, episodes allow concurrency modeling [2], and LPMs additionally allow choices and loops [3]. Declarative patterns allow defining constraints of what should happen first, how often, or in what order [4].

Example sequence, episode, and LPM pattern.
*Only if you are interested: These control-flow constructs are a subset of workflow patterns covered by the workflow initiative (see http://www.workflowpatterns.com/patterns/data/).
How do LPMs fit the picture?
LPMs are behavioral patterns that can model sequence, concurrency, choice, and loop. This realization covers the first important point we made at the start. In the beginning, the purpose of LPMs was the explainability of highly unstructured processes [3]. Remember the buying process in the supermarket and the thousands of customers. For these processes, traditional discovery approaches have difficulty discovering a structured process model, so they would return a spaghetti or a flower model. Hence, LPMs were supposed to have the expressiveness of traditional process models but show what happens locally and ignore the rest. However, practice has shown that LPMs are much more versatile. To prove our third point – LPMs are used to analyze processes – process miners have used them for trace encoding, event abstraction, trace classification and clustering, discovery, or in different use-case scenarios [5-8].
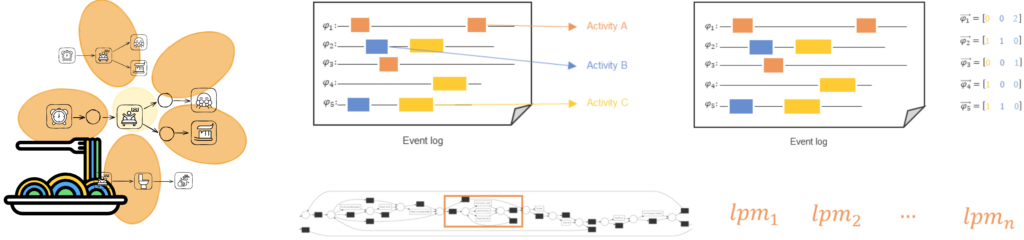
LPMs as replacement for flower and spaghetti process models together with various other applications like event abstraction, trace embedding, and model repair.
Nevertheless, to truly understand LPMs, we have to go back to the event log and make the connection to why LPMs describe process fragments. The simple answer is that they are patterns, but let’s dig deeper.
Let us consider the trace below. When we talk about LPMs, we look at things locally, and this locality can be as small as two events or as big as the entire process execution. Second, LPMs can ignore or skip events. Patterns do not say: “oh, excuse me, I won’t occur unless I cover everything”. No, patterns can occur hidden between events that do not matter as shown in the figure below. So when we search for them, we should be able to handle these situations. If we consider these two crucial parts together, we get to the second point of LPMs: they describe process fragments and not entire processes.
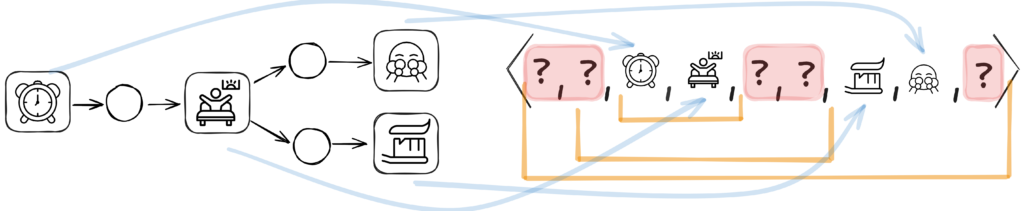
Mapping an LPM onto a trace. Locality is denoted with orange boundaries, activity mappings with blue arrows, and ignored events as question marks in red bounding box.
So far, we have covered LPMs, how they look, and their link to event logs. The next step would be discovery. Several discovery approaches exist [3,9-10], but we won’t discuss those here. We will finish with our opinion of what is next in this research area.
Where do we go from here?
Discovery. As mentioned before, multiple LPM discovery algorithms are available. All of them have strengths and weaknesses, so one way forward is to consider alternative discovery techniques or extensions of existing ones where specific weaknesses are addressed.
Pattern Explosion. On the one hand, LPM discovery, similar to any pattern discovery, suffers from the significant challenge of pattern explosion. In other words, too many patterns or LPMs are built for a human analyst to analyze. On the other hand, LPMs are versatile, meaning they can be used with different end goals in mind. Hence, the ideal solution would be to choose a unique subset of discovered LPMs that best fit the posed research question.
Conformance Checking. After discovering and choosing the optimal set of LPMs, we would like to go back to the data. Which parts of the event log do the LPMs cover? This can enable enhancing the LPMs with data perspective or specific key performance indicators (KPIs).
Much More. The world of LPMs is vast, and there’s always more to explore. If you have questions or ideas, I encourage you to share them in the comments below.
Keywords: behavioral patterns, local process models, complex models.
Icon attribution: The icons used in all figures are listed in https://github.com/VikiPeeva/SharingResources/blob/main/attribution/icons/LPMIntroPADSBlog.md
References
[1] Srikant, R., & Agrawal, R. (1996). Mining sequential patterns: Generalizations and performance improvements. In P. Apers, M. Bouzeghoub, & G. Gardarin (Eds.), Advances in Database Technology—EDBT ’96 (Vol. 1057, pp. 1–17). Springer Berlin Heidelberg. https://doi.org/10.1007/BFb0014140
[2] Leemans, M., & Van Der Aalst, W. M. P. (2015). Discovery of Frequent Episodes in Event Logs. In P. Ceravolo, B. Russo, & R. Accorsi (Eds.), Data-Driven Process Discovery and Analysis (Vol. 237, pp. 1–31). Springer International Publishing. https://doi.org/10.1007/978-3-319-27243-6_1
[3] Tax, N., Sidorova, N., Haakma, R., & Van Der Aalst, W. M. P. (2016). Mining local process models. Journal of Innovation in Digital Ecosystems, 3(2), 183–196. https://doi.org/10.1016/j.jides.2016.11.001
[4] Pesic, M., & Van Der Aalst, W. M. P. (2006). A Declarative Approach for Flexible Business Processes Management. In J. Eder & S. Dustdar (Eds.), Business Process Management Workshops (Vol. 4103, pp. 169–180). Springer Berlin Heidelberg. https://doi.org/10.1007/11837862_18
[5] Mannhardt, F., & Tax, N. (2017). Unsupervised Event Abstraction using Pattern Abstraction and Local Process Models (No. arXiv:1704.03520). arXiv. http://arxiv.org/abs/1704.03520
[6] Pijnenborg, P., Verhoeven, R., Firat, M., Laarhoven, H. V., & Genga, L. (2021). Towards Evidence-Based Analysis of Palliative Treatments for Stomach and Esophageal Cancer Patients: A Process Mining Approach. 2021 3rd International Conference on Process Mining (ICPM), 136–143. https://doi.org/10.1109/ICPM53251.2021.9576880
[7] Leemans, S. J. J., Tax, N., & Ter Hofstede, A. H. M. (2018). Indulpet Miner: Combining Discovery Algorithms. In H. Panetto, C. Debruyne, H. A. Proper, C. A. Ardagna, D. Roman, & R. Meersman (Eds.), On the Move to Meaningful Internet Systems. OTM 2018 Conferences (Vol. 11229, pp. 97–115). Springer International Publishing. https://doi.org/10.1007/978-3-030-02610-3_6
[8] Kirchner, K., & Marković, P. (2018). Unveiling Hidden Patterns in Flexible Medical Treatment Processes – A Process Mining Case Study. In F. Dargam, P. Delias, I. Linden, & B. Mareschal (Eds.), Decision Support Systems VIII: Sustainable Data-Driven and Evidence-Based Decision Support (Vol. 313, pp. 169–180). Springer International Publishing. https://doi.org/10.1007/978-3-319-90315-6_14
[9] Peeva, V., Mannel, L. L., & Van Der Aalst, W. M. P. (2022). From Place Nets to Local Process Models. In L. Bernardinello & L. Petrucci (Eds.), Application and Theory of Petri Nets and Concurrency (Vol. 13288, pp. 346–368). Springer International Publishing. https://doi.org/10.1007/978-3-031-06653-5_18
[10] Acheli, M., Grigori, D., & Weidlich, M. (2019). Efficient Discovery of Compact Maximal Behavioral Patterns from Event Logs. In P. Giorgini & B. Weber (Eds.), Advanced Information Systems Engineering (Vol. 11483, pp. 579–594). Springer International Publishing. https://doi.org/10.1007/978-3-030-21290-2_36
POSTECH Opens the “Wil van der Aalst Data & Process Science Research Center” in Pohang
Pohang University of Science and Technology (POSTECH) in South Korea has named one of its research centers after the PADS chair, prof. Wil van der Aalst. The “Wil van der Aalst Data & Process Science Research Center” reflects his significant contributions to the fields of process mining, business process management, workflow systems, and data science.
The center was opened on November 24th, 2024, on the campus of Pohang University of Science and Technology (POSTECH). A two-day symposium with speakers from industry and academia marked the starting point for the center.

POSTECH (Pohang University of Science and Technology) is a leading research university in South Korea, known for its strong focus on science, engineering, and technology. Established in 1986, it consistently ranks among the top universities globally in these fields. POSTECH is renowned for its cutting-edge research in fields like materials science, physics, chemistry, biotechnology, industrial engineering, and computer science. POSTECH has close ties with industrial partners, particularly in technology and engineering, allowing for real-world application of research. It collaborates with companies like POSCO (a major steel company) and many other global enterprises.
The “Wil van der Aalst Data & Process Science Research Center” aims to become a leading research hub, focusing on both theoretical and applied research in Data Science and Process Science. Professor Minseok Song, who initiated the establishment of the center, states that the three main goals are:
– Conducting high-impact research in Data & Process Science in collaboration with global and local partners.
– Strengthening industry-academic ties, especially in sectors such as manufacturing, service, and finance, where data and process science can drive innovation.
– Building a global research network by collaborating with distinguished international faculty and institutions.

The center is organized into three core research groups:
- Data Science Group – focusing on AI fairness, deep learning, and large-scale computational algorithms.
- Process Science Group – focusing on process mining, digital twins, and process optimization solutions.
- DPS Application Group – focused on applying research outcomes in industries such as manufacturing, finance, and insurance.
The center will play a key role in intensifying the collaboration between RWTH Aachen University and POSTECH. This will include cooperation in the field of process mining between the Process and Data Science (PADS) group at RWTH and the Department of Industrial & Management Engineering at POSTECH. The center will also facilitate student exchanges in the field of data science.
Optimization of Inventory Management in Retail Companies using Object-Centric Process Mining
This post has been authored by Dina Kretzschmann and Alessandro Berti.
Inventory management is crucial for a retails company success, as it directly impacts sales and costs. The core processes affecting inventory management are Order-to-Cash (O2C) and Purchase-to-Pay (P2P) processes. Efficiently managing these processes ensures product availability aligns with customer demand, to avoid understock (leading to lost sales) and overstock (incurring unnecessary costs) situations [1].
Current work on inventory management optimization includes (1) exact mathematical optimization models [2], (2) business management techniques [3], (3) ETL methodologies [4], and (4) traditional/object-centric process mining approaches [5]. However, gaps remain, such as the lack of standardized formalization, static assessments of key performance indicator without root cause analysis, missing links between optimization models and event data, and non-generalizable results [6].
We address these gaps by introducing a generalized object-centric data model (OCDM) for inventory management. This OCDM is enriched with relevant metrics, including Economic Order Quantity (EOQ), Reorder Point (ROP), Safety Stock (SS), Maximum Stock Level (Max), and Overstock (OS), enabling a comprehensive event-data-driven process behavior assessments and the definition of optimization measures (see Figure 1).

Figure 1 Outline of the contributions
We applied our approach to real-life O2C and P2P processes of a pet retailer utilizing the Logomate system for demand forecasting and replenishment, and SAP system for procurement and sales. The pet retailer faces issues in O2C and P2P processes leading to understock and overstock situations worth several million euros. In particular, through the standardized assessment of the interactions between different business objects we identified process behavior leading to understock and overstock situations. We quantified the frequency of these behaviors and conducted a root cause analysis, enabling the definition of optimization measures for the demand forecasting model and adjustments in the supplier contracts. The pet retailer acknowledged the added value of the results. Our approach is reproducible and generalizable with any object-centric event log following the proposed OCDM.
[1] Arnold, D., Isermann, H., Kuhn, A., Tempelmeier, H., Furmans, K.: Handbuch Logistik. Springer (2008)
[2] Tempelmeier, H.: Bestandsmanagement in supply chains. BoD–Books on Demand (2005)
[3] Rahansyah, V.Z., Kusrini, E.: How to Reduce Overstock Inventory: A Case Study. International Journal of Innovative Science and Research Techno (2023)
[4] Dong, R., Su, F., Yang, S., Xu, L., Cheng, X., Chen, W.: Design and application on metadata management for information supply chain. In: ISCIT 2021. pp. 393–396. IEEE (2016)
[5] Kretzschmann, D., Park, G., Berti, A., van der Aalst, W.M.: Overstock Problems in a Purchase-to-Pay Process: An Object-Centric Process Mining Case Study. In: CAiSE 2024 Workshops. pp. 347–359. Springer (2024)
[6] Asdecker, B., Tscherner, M., Kurringer, N., Felch, V.: A Dirty Little Secret? Conducting a Systematic Literature Review Regarding Overstocks. In: Logistics Management Conference. pp. 229–247. Springer (2023)
Sustainable Logistics Powered by Process Mining
This post has been authored by Nina Graves.
In today’s business landscape, companies are faced with the urgent need to make their processes more sustainable. Process mining techniques, known for their capability to provide valuable insights and support process improvement, are gaining increasing attention to support the transformation towards more sustainable processes [1]. To this end, we explore how process mining techniques can be enhanced to better support the transformation to more sustainable business processes. Initially, we identified the types of business processes that are most relevant for sustainability transformation: particularly production and logistics processes [2]. However, these processes are often challenging to analyse because (object-centric) process mining techniques make certain assumptions that do not always hold true:
- Every relevant process instance can be “tracked” in the event log using a unique identifier.
- The execution of an event depends on time or the “state” of the involved objects (previously executed activities, object attributes, object relationships).
- Two process executions are independent of each other.

Figure 1 – Decoupled Example Process (SP: Sub-Process)
Now imagine you are a company selling pencil cases (Figure 1):
You buy cases and pens from your suppliers (SP 1), adjust the cases and add the pens to create the final product (SP 2). Finally, you fulfil the incoming customer orders by sending the number of pencil cases you demand (SP 3). Additionally, you must ensure you always have enough pens, cases, and pencil cases to cover the incoming customer demand without keeping inventory levels too high. You would like to support your processes using PM techniques both to support your process and to analyse your scope3 emissions for the pencil cases you sell to end customers. You now face three problems: 1) You cannot detect the full end-to-end process, as there is no unique identifier for either the products you buy or the ones you sell. 2) The quantity of products you are considering varies between the sub-processes and even within the individual process executions (e.g. the demand in two customer orders is not necessarily the same). 3) You cannot consider the overall inventory management process, as it depends on the available quantities of products you cannot explicitly capture in the event log.
To bridge this gap, we are currently working on the extension of process mining techniques to support the perks of production and logistics processes. To do so, we are developing process mining techniques for the joint consideration of decoupled sub-processes [2]. Combining them with decoupling points (triangles in Figure 1), we allow for the joint consideration of (sub-)processes not combined by identifiable objects as well as another way of describing the state a process is in. This quantity state describes the count of items associated with one of the decoupling points and can be changed by executing specific events (Figure 2), e.g., “add to inventory” increases the number of products available in the incoming goods inventory.

Figure 2 – Development of the Stock Levels over Time (Quantity State)
The extension to process mining techniques we are working on allows for a more explicit consideration of quantities and their impact on the execution of events, e.g., the execution of “place replenishment order” depends on the number of pencils and cases available in the incoming goods inventory and the number of finished pencil cases. We are excited to dive deeper into this area of quantity-related process mining, as it offers many new possibilities for combining “disconnected” sub-processes and detecting quantity dependencies across multiple process executions.
References
[1] Horsthofer-Rauch, J., Guesken, S. R., Weich, J., Rauch, A., Bittner, M., Schulz, J., & Zaeh, M. F. (2024). Sustainability-integrated value stream mapping with process mining. Production & Manufacturing Research, 12(1), 2334294. https://doi.org/10.1080/21693277.2024.2334294
[2] Graves, N., Koren, I., & van der Aalst, W. M. P. (2023). ReThink Your Processes! A Review of Process Mining for Sustainability. 2023 International Conference on ICT for Sustainability (ICT4S), 164–175. https://doi.org/10.1109/ICT4S58814.2023.00025
[3] Graves, N., Koren, I., Rafiei, M., & van der Aalst, W. M. P. (2024). From Identities to Quantities: Introducing Items and Decoupling Points to Object-Centric Process Mining. In J. De Smedt & P. Soffer (Eds.), Process Mining Workshops (Vol. 503, pp. 462–474). Springer Nature Switzerland. https://doi.org/10.1007/978-3-031-56107-8_35
New Gartner Magic Quadrant for Process Mining Platforms Is Out
In 2023, Gartner published the first Magic Quadrant for Process Mining. This reflected that analyst firms started considering process mining as an important product category.
On April 29th 2024, the new Gartner Magic Quadrant for Process Mining Platforms was published. The Magic Quadrant (MQ) is a graphical tool used to evaluate technology providers, facilitating smart investment decisions through a uniform set of criteria. It categorizes providers into four types: Leaders, Visionaries, Niche Players, and Challengers. Leaders are well-executed and positioned for future success, whereas Visionaries have a clear vision of market trends but lack strong execution. Niche Players focus on specific segments without broader innovation, and Challengers perform well currently without a clear grasp of market direction.

Prof. Wil van der Aalst (c) PADS
In the 2024 MQ, five new vendors were added, and two were dropped, leading to 18 vendors being compared. Twelve additional vendors received an honorable mention. Overall, there are currently around 50 process mining vendors (see www.processmining.org). According to Gartner, “By 2026, 25% of global enterprises will have embraced process mining platforms as a first step to creating a digital twin for business operations, paving the way to autonomous business operations. Through 2026, insufficient business process management maturity will prevent 90% of organizations from reaching desired business outcomes from their end-to-end process mining initiatives.” This illustrates the relevance of the Process Mining MQ.
For the second year in a row, Celonis has been the highest ranked in terms of completeness of vision and ability to execute. Other vendors listed as leaders are Software AG, SAP Signavio, UiPath, Microsoft, Apromore, Mehrwerk, Appian, and Abbyy. The basic capabilities provided by all tools include process discovery and analysis, process comparison, analysis and validation, and discovering and validating automation opportunities. New and important capabilities include Object-Centric Process Mining (OCPM), Process-Aware Machine Learning (PAML), and Generative AI (GenAI).
For more information, download the report from https://celon.is/Gartner.
Conformance Checking Approximation Using Simulation
This post is by Mohammadreza Fani Sani, Scientific Assistant in the Process and Data Science team at RWTH Aachen. Contact her via email for further inquiries
Conformance checking techniques are used to detect deviations and to measure how accurate a process model is. Alignments were developed with the concrete goal to describe and quantify deviations in a non-ambiguous manner. Computing alignments has rapidly turned into the de facto standard conformance checking technique.
However, alignment computations may be time-consuming for real large event data. In some scenarios, the diagnostic information that is produced by alignments is not required and we simply need an objective measure of model quality to compare process models, i.e., the alignment value. Moreover, in many applications, it is required to compute alignment values several times.
As normal alignment methods take a considerable time for large real event data, analyzing many candidate process models is impractical. Therefore, by decreasing the alignment computation time, it is possible to consider more candidate process models in a limited time. Thus, by having an approximated conformance value, we can find a suitable process model faster.
By providing bounds, we guarantee that the accurate alignment value does not exceed a range of values, and, consequently we determine if it is required to do further analysis or not, which saves a considerable amount of time. Thus, in many applications, it is valuable to have a quick approximated conformance value and it is excellent worth to let users adjust the level of approximation.
In this research, we extend the previous work by proposing to use process model simulation (i.e., some of its possible executable behaviors) to create a subset of process model behaviors. The core idea of this paper is to have simulated behaviors close to the recorded behaviors in the event log. Moreover, we provide bounds for the actual conformance value.
Fig 1. A schematic view of the proposed method.
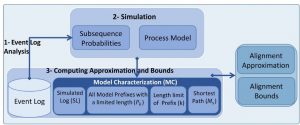
Using the proposed method, users can adjust the amount of process model behaviors considered in the approximation, which affects the computation time and the accuracy of alignment values and their bounds. As the proposed method just uses the simulated behaviors for conformance approximation, it is independent of any process model notation.
Table 1. Comparison of approximating the conformance checking using the proposed simulation method and the sampling method.
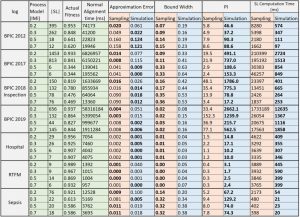
Since we use the edit distance function and do not compute any alignment, even if there is no reference process model and just some of the correct behaviors of the process (e.g., some of the valid variants) are known, the proposed method can approximate the conformance value. The method additionally returns problematic activities, based on their deviation rates.
We implemented the proposed method using both the ProM and RapidProM platforms. Moreover, we applied it to several large real event data and process models. We also compared our approach with the state-of-the-art alignment approximation method. The results show that the proposed simulation method improves the performance of the conformance checking process while providing approximations close to the actual values.
If you are interested in this research, please read the full paper at the following link: https://ieeexplore.ieee.org/document/9230162
If you need more information please contact me via fanisani@pads.rwth-aachen.de
JXES – JSON support for XES Event Logs
This post is by Madhavi Shankara Narayana, Software Engineer in the Process and Data Science team at RWTH Aachen. Contact her via email for further inquiries.
Process mining assumes the existence of an event log where each event refers to a case, an activity, and a point in time. XES is an XML based IEEE approved standard format for event logs supported by most of the process mining tools. JSON (JavaScript Object Notation), a lightweight data-interchange format has gained popularity over the last decade. Hence, we present JXES, the JSON standard for the event logs.
JXES Format
JSON is an open standard lightweight file format commonly used for data interchange. It uses human-readable text to store and transmit data objects.
For defining the JSON standard format, we have taken into account the XES meta-model represented by the basic structure (log, trace and event), Attributes, Nested Attributes, Global Attributes, Event classifiers and Extensions as shown in Figure 1.

The JXES event log structure is as shown in Figure 2.

The plugin for ProM to import and export the JSON file consists of 4 different parser implementations of import as well as export. Plugin implementations are available for Jackson, Jsoninter, GSON and simple JSON parsers.
We hope that the JXES standard defined by this paper will be helpful and serve as a guideline for generating event logs in JSON format. We also hope that the JXES standard defined in this paper will be useful for many tools like Disco, Celonis, PM4Py, etc., to enable support for JSON event logs.
For detailed information on the JXES format, please refer to https://arxiv.org/abs/2009.06363
