


Quelle: Eigene Darstellung
Am 22. Januar 2026 hieß das FDM-Team die FDM-Community der RWTH Aachen zum ersten FDM-Netzwerktreffen des Jahres willkommen. Die monatliche Veranstaltung findet jeden vierten Donnerstag online oder persönlich statt und bietet allen FDM-Interessierten die Möglichkeit zum Austausch und zur Diskussion von Praxisbeispielen.
Im Mittelpunkt des Januartreffens stand der Vortrag „Data Mesh for RDM in the Engineering Sciences“ von Mario Moser vom Werkzeugmaschinenlabor (WZL) der RWTH. Darin gab er spannende Einblicke in sein Promotionsthema und stellte als Teil des NFDI4ING-Konsortiums konzeptionelle Überlegungen und Ausgestaltung zum Einsatz des Data-Mesh-Ansatzes im FDM der Ingenieurwissenschaften vor.
Effizient vernetzt im Science-Speed-Dating
Wie bei den FDM-Netzwerktreffens üblich, startete die Veranstaltung mit einem Science-Speed-Dating. In zwei kurzen Runden à vier Minuten kamen die Teilnehmenden in Kleingruppen ins Gespräch, tauschten sich zunächst kurz über ihren Hintergrund aus und diskutierten ihre Erfahrungen zur Wiederverwendung von Forschungsdaten. Die Gedanken zur Auffindbarkeit, Nutzung und Qualität von Forschungsdaten wurden auf einem gemeinsamen Miro-Board gesammelt.
Vortrag: Data-Mesh für FDM in den Ingenieurwissenschaften
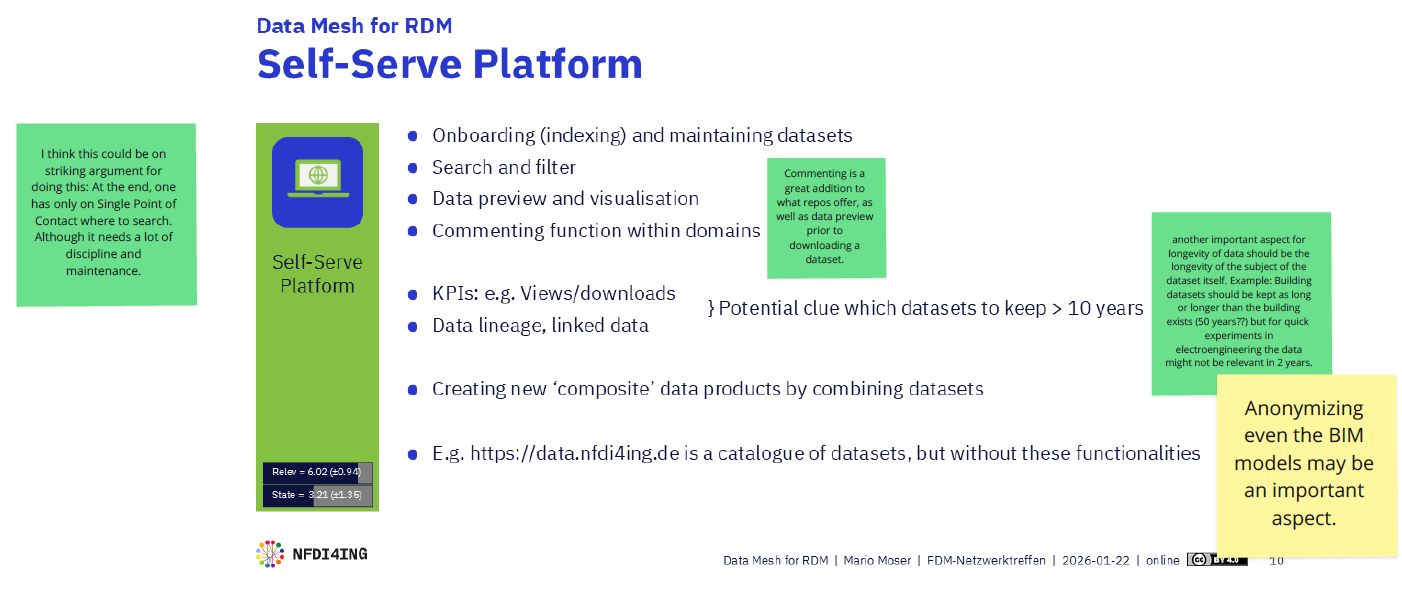
Den Kern des Treffens bildete der Vortrag von Mario Moser, der Einblicke darin gab, wie der Data-Mesh-Ansatz den Austausch und die Wiederverwendung von Daten in den Ingenieurwissenschaften erleichtern kann. Dieser Ansatz aus dem ursprünglich industriellen Datenmanagement kombiniert technische, organisatorische und soziale Bestandteile, um Forschende beim effektiven Teilen und Nutzen von Forschungsdaten zu unterstützen.
Laut der Kernidee werden Verantwortung und Datenverwaltung dezentral organisiert. Die Daten liegen in verschiedenen Repositorien – institutionell, disziplinspezifisch oder generisch –, welches gute Praxis im wissenschaftlichen Datenmanagement darstellt, allerdings auch die Suche/Recherche eines Datensatzes aufgrund der Vielzahl von Repositorien erschwert. Das Forschungsumfeld weist ebenfalls dezentralisierte Eigenschaften auf und verändert sich dynamisch: Forschungsdaten werden kontinuierlich erfasst, sowohl in Projekten als auch über längere Zeiträume hinweg. Verschiedene Forschungseinrichtungen und Lehrstühle sind über Projekte miteinander vernetzt, ohne dass eine strikte hierarchische Struktur vorgeschrieben ist. Datenqualität ist für Nachnutzung relevant, wird in Repositorien aber oftmals nicht abgebildet.
Im Data Mesh für Forschungsdatenmanagement wird inhaltliche Verantwortlichkeit für erstellte Daten und eventuelle Rückfragen bei den Forschenden angesiedelt (‚Domain Ownership‘), während Repositoriumsbetreiber für die technische Bereitstellung und Zugänglichkeit verantwortlich sind. Um die verteilten Datensätze in den verschiedenen Repositorien dennoch an einer Stelle auffindbar zu machen, werden die Datensätze aus den verschiedenen in definierter Form (‚Data Products‘) mittels API auf einer zentralen Plattform (‚Self-Serve Platform‘) dargestellt. Dabei werden Regeln der Data Governance und Datenqualität angewendet und am Datensatz dargestellt. Der Ansatz fügt sich in die bestehende Forschungslandschaft ein, indem vorhandene Daten, Werkzeuge und Strukturen – beispielsweise im Rahmen von NFDI4ING für die Ingenieurwissenschaften – können genutzt und in ein dezentral organisiertes Netzwerk eingebunden werden. So entsteht eine Infrastruktur, die die Datenarbeit in der Forschung flexibel, kollaborativ und nachhaltig unterstützt.
Technisch ist die Umsetzung vergleichsweise einfach, organisatorisch erfordert sie jedoch fortlaufende Abstimmung innerhalb fachlicher Domains, bspw. zu Standards und Domain-spezifische Datenqualitätskriterien für Datensätze. Der Ansatz ergänzt die Infrastruktur als zusätzliche Schicht, erhöht jedoch nicht deren Resilienz.
Wir bedanken uns herzlich bei Mario Moser für den spannenden Vortrag und den aufschlussreichen Einblick in den Data-Mesh-Ansatz für die Ingenieurwissenschaften.
Quelle: Mario Moser
Diskussion: Potenziale und Grenzen des Data Mesh
In der anschließenden Diskussion wurden die Grenzen des Data-Mesh-Ansatzes kritisch beleuchtet. Einigkeit bestand darin, dass die Wiederverwendbarkeit von Forschungsdaten und auch deren Datenqualität stark vom jeweiligen Anwendungskontext abhängt und durch Infrastrukturkonzepte allein nicht garantiert werden kann. Langzeitverfügbarkeit und Datenqualität sind zentrale Herausforderungen, ebenso wie bei den Repositorien, die das Data Mesh vernetzt.
Außerdem wurde die Motivation zur Beteiligung thematisiert. Einerseits wurde angenommen, dass der zusätzliche Aufwand für viele Forschende eine wesentliche Hürde darstellt. Andererseits wurde das große Potenzial des Data-Mesh-Ansatzes hervorgehoben: Die wissenschaftliche Sichtbarkeit der eigenen Daten lässt sich durch die Verknüpfung über APIs mit anderen Ressourcen, die Einbindung zusätzlicher Informationen sowie den geförderten Austausch und Diskussionen zu den Datensätzen deutlich steigern. Solch ein Austausch auf der Datenplattform bietet die Chance, dass Communities Datensätze auch dann noch verständlich halten, wenn die ursprünglichen Autorinnen und Autoren nicht mehr in der Forschung aktiv sind.
Mehr erfahren
Sie sind am FDM-Netzwerk interessiert und möchten auf dem aktuellen Stand gehalten werden? Dann abonnieren Sie die Mailingliste „DataStewards@RWTH“.
Bei Fragen zum FDM-Netzwerk oder zu Themen rund um das Forschungsdatenmanagement stehen wir Ihnen jederzeit gerne zur Verfügung. Das FDM-Team freut sich über Ihre Nachricht und hilft Ihnen gerne weiter!
Verantwortlich für die Inhalte dieses Beitrags sind Lina-Louise Kaulbach und Ute Trautwein-Bruns.




Schreibe einen Kommentar
Du musst angemeldet sein, um einen Kommentar abzugeben.