


Source: Freepik
In the DFG-funded project “Heuristics for Heterogeneous Memory” (H2M), RWTH Aachen University and the French project partner Inria are jointly developing support for new memory technologies such as High Bandwidth Memory (HBM) and Non-Volatile Memory (NVM). These technologies are increasingly used as additional memory in HPC systems alongside the common Dynamic Random Access Memory (DRAM). HBM offers higher bandwidth than classic DRAM but is also much smaller. NVM provides larger capacities but is slower compared to DRAM. The different characteristics and capacity limits thus raise the question of how systems with heterogeneous memory can be used efficiently and in which memory data should be stored.

Christian Terboven, Brice Goglin, Emmanuel Jeannot, Clément Foyer, Anara Kozhokanova and Jannis Klinkenberg
Source: Own illustration
To use the new memory technologies, applications currently must be heavily modified and platform- or manufacturer-specific application programming interfaces (APIs) must be used.
Since the beginning of the 2021 project, H2M has been pursuing the goal of providing portable interfaces to identify available memories and their properties and to enable access. Based on this, allocation abstractions and heuristics are developed to give application developers as well as runtime systems control in which storage data is placed and when data should be moved between different types of storage. In our blog post 2021, we already presented the beginning of the project. At that time, it was still unclear how abstractions and heuristics should look like. Now the researchers are already a big step further and have developed these allocation abstractions.
With the right traits to the right memory
The idea is to abstract the commonly used memory allocation functions such as malloc (in C) and new (in C++) by a new allocation function (h2m_alloc_w_traits). With this, application developers can pass additional properties (so-called traits) to an allocation, which could describe how the data is used in the course of the application or how the data will be accessed or which requirements the allocation must fulfil. This can be seen in the following example.
int err;
double* data_item;
size t N = 1000 * sizeof(double); // desired size (in bytes)
// Specify allocation traits (requirements and hints)
h2m_alloc_trait_t traits[5] = {
h2m_atk_access_mode, h2m_atv_access_mode_readwrite,
h2m_atk_access_origin, h2m_atv_access_origin_multiple_threads,
h2m_atk_access_pattern, h2m_atv_access_pattern_strided,
h2m_atk_access_stride, 3 /* in bytes */,
h2m_atk_access_freq, 2000, /* e.g., accesses per sec */};
// Finally allocate memory
data_item = (double*) h2m_alloc_w_traits(N, &err, 5, traits);
In this code example, it is specified for the allocation that the data is accessed by multiple threads in a reading and writing manner, and it is expected to be in a non-linear fashion, but with a stride of 3. This means that only every 3rd value is used. Threads are independent instruction flows that can be processed concurrently and are often used in parallel programming to speed up applications.
As Figure 1 shows, the H2M runtime system can then use strategies to determine the appropriate memory to store the data. This considers both traits and the memory technologies available in the system. Among other things, H2M provides simple base strategies, but also offers the possibility to create and use user-defined strategies through an interface.
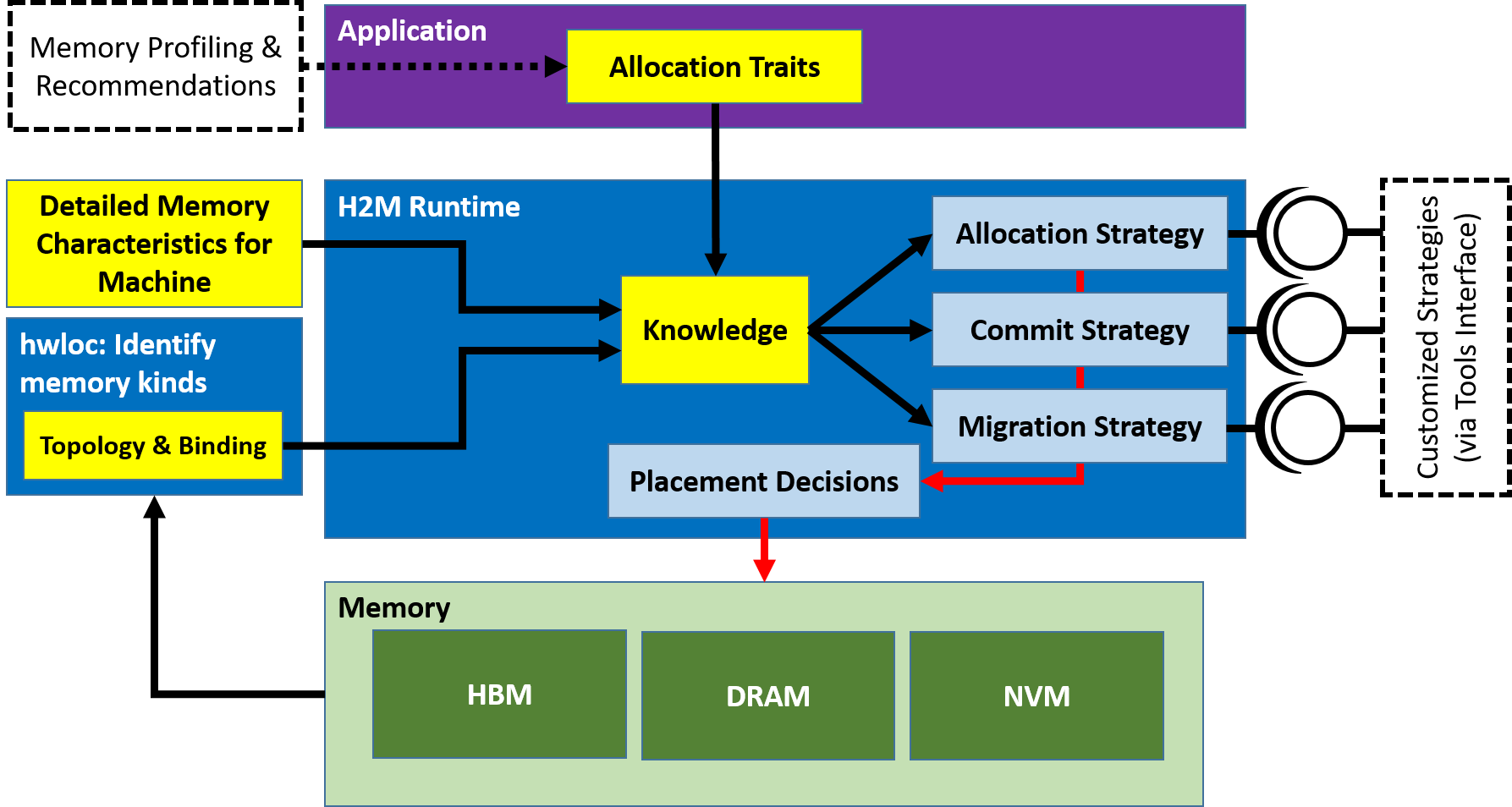
Figure 1: Overview of H2M components and interaction with application and system environment Source: Own illustration
Broad-based – evaluation on several architectures and current research direction
The new concept is being evaluated with various proxy applications, so-called mini-apps, and benchmarks on different architectures. Examples are Intel’s KNL architecture, which is equipped with MCDRAM (HBM) memory modules in addition to DRAM. This is smaller but offers a higher bandwidth. In addition, an architecture has been evaluated that has large amounts of Intel Optane DC Persistent Memory (NVM or non-volatile memory) in addition to the usual DDR4, which is slower but provides more capacity in return.
Up to now, the focus of the research was on scenarios in which data objects were allocated once in certain memory types and stay there for the entirety of the program execution. However, current and future research is also investigating the extent to which dynamic movement of data between memory types at execution time can increase efficiency. This is interesting, for example, when applications consist of several execution phases in which the data is used differently or in which access patterns to data change significantly.
Responsible for the content of this article are Janin Vreydal and Jannis Klinkenberg.



