


Source: Unsplash
The Archive service enables RWTH employees to store data on a tape robot system for the long term. Archiving data in this way is primarily used to store data that, once stored, should also be stored in this form for the long term.
In the past, data inventories were stored here, primarily documenting measurement results, completed projects or project briefs. With the changes in the funding landscape, which among other things also rethink and demand the keeping of research data, the Archive service is also being rethought. This is partly because the current inventory system will be decommissioned in the summer of 2022 and partly because there is a need to hold data in a structured way in the future. So it’s time for a changeover.
But don’t worry, the data will not be lost: All data in the previous archive system will be migrated so that it can still be accessed in the future. This article explains what this archive migration is all about and what you can expect.
Technology Change – from Tape to Object Storage
Due to changes in technology and the funding landscape, the archive data will be migrated to an S3 object storage infrastructure from summer 2021. The advantages of this storage infrastructure over the tape robot system are not only the simple and fast delivery of data via the S3 protocol, but also access to the archived data. Whereas retrieval – i.e. retrieving the archived data – used to be quite time-consuming, this will become more convenient and efficient in the future. In addition, security against data loss will be significantly increased due to the geographical distribution of storage locations (keyword geo-redundancy).
Archive – a Storage Facility for Diverse Data
As digitization continues and the variety of data continues to grow, not only does the amount of data increase, but so do the requirements for storing it over time. We all know it: If we had no structure on our storing media or devices, retrieval would be much more difficult, not to mention editing, sharing and viewing the data. The archive as we know it contains data from research, teaching and administration on the many archive nodes without higher-level sorting criteria and without qualification or classification. This is to change with the migration, which offers this opportunity.
At best, only the person who archived the data still knows what it was about. On the part of the users, this requires that they themselves maintain an overview that provides information about archived data or keep track of it. With migration, this important information is stored in the form of metadata directly with the inventory to be archived.
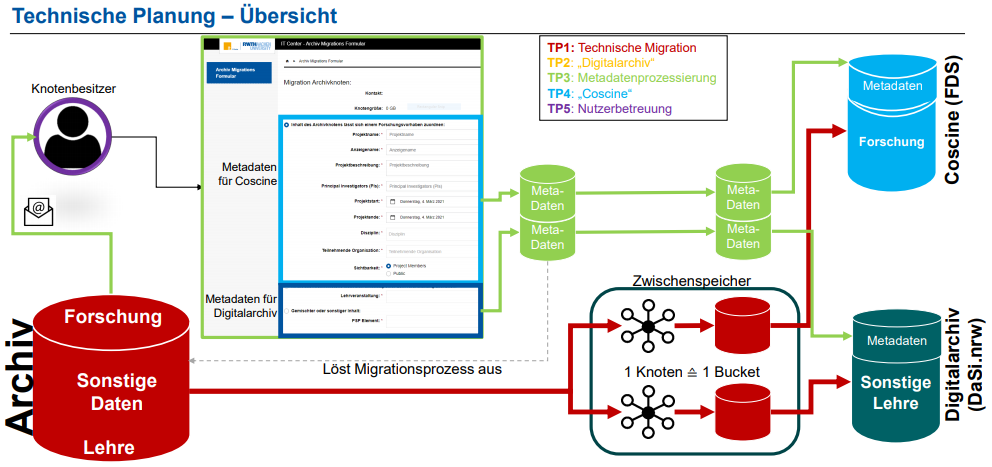
Overview of the technical planning showing the migration process of archive data to the destinations Coscine and Digital Archive.
Source: Own illustration
Where is the Data Migrated to?
This is where the dedicated storage Coscine and Digital Archive come into play, as well as metadata entry. With the migration project, the current archive node owners are called upon to enter metadata for the archive nodes to be migrated: Based on the metadata, the existing archive nodes are classified. The users thus decide whether it is research data that will be migrated to Coscine with the corresponding metadata set, or whether the digital archive is the right storage location for other data, e.g. from teaching and administration. Once the metadata has been captured, it is first temporarily saved and then, finally merged and stored in the migration process with the data to be migrated in a so-called bucket in the target system.
Migration Project with Participation Structure
This extensive conversion requires a well-structured organization – both within RWTH Aachen University and the IT Center. For this reason, the “Archive Migration” project was launched. The entire project was divided into five sub-projects, with the departments IT Process Support Research & Teaching (IT-PFL) and Systems & Operations (SuB) are involved.
In addition to the technical migration of the archive nodes from the archive system to the new infrastructure, development work is also being carried out in the software area. On the one hand, SeViRe is being expanded to
include functions related to the digital archive, while at the same time the development of metadata processing is being advanced. With Coscine, the colleagues have already been able to make significant preparations for the archiving of research data.
The technical and process-related subprojects are supplemented by a dedicated communications subproject. The focus here is on providing information to users and support staff. In the course of this, information events have already been organized to provide administrators and power users with comprehensive information. In addition, an interest group has been initiated, in which the experiences of archive users are taken into account as well as requirements, expectations and wishes are listened to in order to be able to take them into account.
As you might have guessed, this article was just the starting signal for the archive migration. If you want to stay up to date, follow our hashtag #ArMiRWTH. We’ll let you know as soon as we have news.
Responsible for the content of this article are Lukas C. Bossert and Nicole Filla.




Research data
Hello Elqatary,
thank you for your comment.
If you have any questions about this topic, please feel free to contact us at the IT-Service Desk.
Kind regards, the IT Center Blog Team.