


Source: Pixabay
***Update***
Currently, the migration of the archive data is still ongoing and will last beyond the extended project goal. Users whose data has not yet been migrated will be contacted by email. You can check the current status of the migration on our reporting page. (*)
The “Archive Migration” project, in which we are transferring archived data from the TSM inventory system to the new target systems DigitalArchive and Coscine, is developing more and more into a mammoth project. Despite extensive planning of the five sub-projects and comprehensive communication on the classification of the archived nodes, unforeseeable problems occurred and continue to occur in the technical implementation of the migration, which are now leading to a project delay.
Planned project end 31.12.2022
Due to the accumulated problems and the constant need to adapt our workflows, the end of the project is expected to be delayed until December 31, 2022. At this point, however, it is very important for us to inform all those affected that the archived data is safe with us. The top priority in archive migration is to preserve the integrity of the data to be migrated.
With this blog post, we would like to provide transparent insight into the challenges and technical issues we have encountered so far in archive migration.
Even though we can only describe an intermediate step today, we would like to thank all node contact persons and backup admins who have taken over the classification of archive nodes (research or course data or other data) on behalf of, among others, departed node contact persons. In this way, they created the basis for being able to migrate the archive nodes to the correct target systems. Nevertheless, in many cases, rework was necessary here as well, so that even now it comes to the collection of metadata of individual nodes.
In the process, we found that nodes were also classified even though they did not hold any data at all. Since it is technically not possible to migrate these because there is no data that can be migrated, these nodes are given the status “No Migration”. The respective node contact persons are informed about this by e-mail.
Ongoing new problems with the start of technical migration
The original plan to automatically migrate archived data from the TSM inventory system to the new DigitalArchive and Coscine target systems did not work as planned due to a variety of technical issues. This circumstance describes the primary reason for the project delay. Due to the large volume of data to be migrated of over 1,690,722 GB (approx. 1,7 PB) with over 785 million objects, there is inevitably a certain amount of data heterogeneity, so we have continuously run into new problems since the start of the technical migration that we could not have foreseen in this way.
We would like to elaborate on the biggest challenges and problems we have encountered so far.
- Platform problems on the existing system:
In the existing system TSM, data could be imported into a Windows or Linux node. Both systems require completely different adaptations and every “exception” that we encounter with the archive nodes always has to be corrected for both platforms. - Heterogeneity of the stored data, e.g. encoding of file names:
The existing system TSM does not operate according to the encoding standard UTF-8, so that file names with special characters or similar are not output correctly and we could not migrate them correctly. Since the character encoding system of TSM is not documented, we first had to spend a lot of time decoding to enable a correct migration. For the target systems, we are working with the UTF-8 standard, so in the future this problem will no longer occur. - Encrypted nodes:
In the existingsystem there was the possibility to encrypt nodes via the TSM. Only those in possession of the key could access the data. Even we in the IT Center do not know this key and there is no way for us to access and migrate this data. We will individually contact the contact persons of the nodes for whose nodes we detect such encryption and inform them about the possibility of “self-initiated migration”. - Empty nodes that were nevertheless classified:
Thankfully, the call for classification of archive nodes was followed. However, nodes were also classified where we have now determined that they do not contain files that we can migrate. For this reason, we are once again individually contacting the appropriate contact persons of the nodes about this, that we will give their empty nodes a status of “No Migration” and no migration will take place. Where there is no data, no data can be migrated. Of course, those affected will have another opportunity to check this status. More details will be communicated in the corresponding e-mail to those affected. - Final notification about migrated nodes:
Due to an incorrectly set script, the contact persons of the nodes were informed in June 2022 that their data had supposedly been migrated. The link in the e-mail led to the target system Coscine, but only to the top level of the personal area, without any indication of which data had been migrated. We were able to quickly identify and correct the error, so we were able to contact the appropriate people through various channels. Once again, we apologize for the volume of e-mails and the irritation. To make it easier to see which archive node data has been successfully migrated, we will include the project name in the notification e-mail. - Archive node access error (error code 500):
The migrated research data is migrated to the so-called RDS-NRW share, which has a very high level of protection thanks to geo-redundancy across different locations in NRW. During an update of the firewall firmware of this RDS-NRW share at the end of August 2022, a faulty configuration occurred. This resulted in error code 500 being displayed in Coscine. The system has since been configured correctly and migrated research data can be accessed again. - Very large archive nodes:
The fact that very many and large data come together in a research context is demonstrated by archive nodes, which are our “large candidates” with over 90 TB to 190 TB. We cannot migrate these nodes in the course of the envisaged automated workflow, but have to perform the steps of downloading from TSM and uploading to the target system manually. This means that the migration progress has to be also consistently monitored. Since we are dealing with a tape storage system in the existing system TSM, reading out the tapes is a mechanical process that takes a correspondingly long time for such large nodes. [If you want to know how such a tape storage system works, watch the video concerning this topic.] - Archive nodes with very many objects:
In addition to huge archive nodes, archive nodes with very many individual objects also cause us problems. Almost 100 nodes have more than 10 million objects, which is not only time consuming (reading data from TSM and uploading it again), but also technically challenging.
These problems are in themselves manageable in isolation, but they have slowed us down accordingly in the technical migration.
Thanks to the wonderful support and diverse know-how of our colleagues, we have found ways and means to move forward with the archive migration. In addition to ongoing adjustments to scripts and workarounds, staggering of migration phases, and the deployment of more staff, we are now well on our way and confident that we will be able to send more and more completion notifications to the contact persons of the nodes on an ongoing basis.
Viewable reporting available
In addition, we are steadily working on processing archive migration requests as well as expanding our archive migration reporting. We ask all users for a little indulgence and patience during processing. The archive will continue to be available on a read-only basis. If necessary, data can be downloaded from the archive. Only the upload is now only possible via the DigitalArchive and Coscine.
Naturally, there is a lot of interest in how far the respective archive nodes are in the migration. For this reason, we have developed a reporting for all interested parties. The reporting page is updated hourly and shows the progress of the last hour as well as compared to the previous day. In order to work as efficiently as possible, we have introduced a system of classification and status, using abbreviations such as “migcResearch” (successful migration to Coscine, no completion notification sent yet). On the page we explain what is behind it and how to read the reporting.
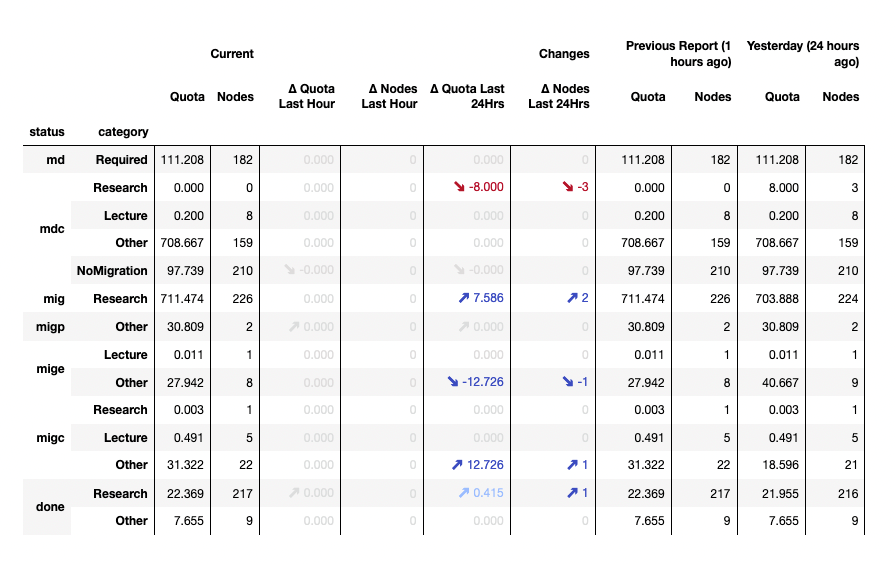
View of Reporting
Source: Own illustration
In the “Individual Node Report” overview, you can see the status of your archive node based on the ID, which can be read from the URL of the metadata form.
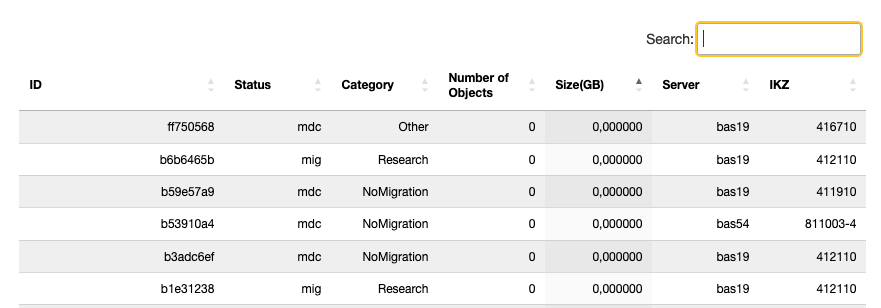
View of the “Individual Node Report”
Source: Own illustration
We apologize for the delay to all those who were worried about their archive nodes in the meantime. Unfortunately, it took a little longer this time, but things are looking good and we are doing our best to safely and securely transfer all data to the designated target systems.
Responsible for the content of this article are Lukas C. Bossert and Nicole Filla.




Wie sieht aktuell der Zeitplan aus?
bei einem unserer Knoten steht migration error, bei dem anderen awaiting migration?
es war ja geplant, die ende letzten Jahres alle migriert zu haben?
Könnt ihr hier im Blog bitte ein update schreiben?
Hallo Matias,
vielen Dank für deinen Kommentar.
Wir leiten die Fragen gerne an die Fachabteilung weiter und melden uns wieder.
Viele Grüße
das IT Center Blog Team
Hallo Matias,
wir haben von der Fachabteilung die Rückmeldung erhalten, dass ursprünglich geplant war, das Projekt bis Ende 2022 fertigzustellen, was sich jedoch aufgrund technischer Probleme verzögert.
Die Knotenansprechpersonen der noch nicht migrierten Knoten werden in Kürze per E-Mail informiert. Der Status migerror soll kein Grund zur Sorge sein. Die Integrität der Daten ist zu jedem Zeitpunkt gewahrt.
Technische Probleme, die diesen Status nach sich ziehen, sind der Grund für die Verzögerung.
Ein Update dazu für den Blog ist bereits in Planung.
Bitte entschuldige die Verzögerung.
Viele Grüße,
das IT Center Blog Team